|
|
OBTENCIÓN DE PREDICCIONES Y ANÁLISIS DE RESIDUOS
El modelo permite generar predicciones para el valor esperado o para un valor individual de la variable dependiente (Y) asociado a un valor dado de la variable independiente (X). En ambos casos la predicción puntual es la misma y se obtiene sustituyendo en el modelo estimado el valor X0 para el cual se desea realizar la predicción.
Para obtener el intervalo de confianza de los pronósticos y/o contrastar si puede aceptarse un determinado valor de Y condicionado a un valor X0 es necesario calcular el error estándar de la predicción, el cual dependerá del valor pronosticado:
- Predicción del valor esperado de Y para X=X0,

- Predicción del valor individual de Y para X=X0,

Para obtener las predicciones se debe acceder al cuadro de diálogo Regresión Lineal: Guardar nuevas variables con el botón Guardar:

- El bloque Valores pronosticados presenta una serie de opciones que permiten guardar en el archivo activo las predicciones No tipificadas y Tipificadas correspondientes a los casos incluidos en la estimación y las predicciones correspondientes a los casos no incluidos obtenidas a partir del modelo estimado. Con la opción Corregidos se obtienen los valores ajustados para cada caso calculados a partir de la recta estimada exluyendo el caso (por lo tanto, se realizan tantas estimaciones de la recta como casos incluidos en la muestra). La opción E.T. del pronóstico promedio proporciona el error típico de las predicciones del valor esperado.
- El bloque Residuos permite guardar en el archivo activo los residuos correspondientes a los casos incluidos en la estimación No tipificados, Tipificados y Estudentizados. Con las opciones Eliminados y Eliminados estudentizados se guardan los residuos correspondientes a las regresiones obtenidas excluyendo el caso correspondiente.
- El bloque Intervalos de pronóstico calcula intervalos de confianza para las predicciones de la Media y/o los Individuos para el nivel de confianza deseado (95% de confianza por defecto).
- Si se desea guardar estos resultados en un archivo nuevo se activa la opción Estadísticos de los coeficientes y se indica el nombre del archivo.
EJEMPLOS
Ejemplo 1.
Con las variables Peso y Est (estatura) del archivo Encinf.sav analizadas en el último ejemplo del capítulo 3* estime el modelo de regresión lineal simple que explica el comportamiento del Peso (variable dependiente) en función de la Est (variable independiente). Realice la estimación con los 100 primeros casos.
Con la secuencia Analizar > Regresión > Lineal aparece el correspondiente cuadro de diálogo en el que se seleccionan la variable Peso como Dependiente y la variable Est como Independiente. En el recuadro Variable de selección se introduce la variable Enc (número de encuesta) y con el botón Regla se abre el cuadro de diálogo Regresión Lineal: Establecer regla donde se introduce la condición 'menor o igual que 100'.

Los resultados que se obtienen son:

En el cuadro resumen del modelo se observa que: r=0,883, R2=0,78 (obsérvese que R2 es igual a r al cuadrado) y Su=6,0638. El coeficiente de determinación indica que el 78% de la variación total del peso en la muestra queda explicada por el modelo estimado y, por lo tanto, el modelo proporciona un buen ajuste.

El cuadro Coeficientes presenta los siguientes resultados:
- Modelo estimado:
=-132,783 + 1,148Est.
- Errores típicos (errores estándar) de las estimaciones de los parámetros
y
: Sa=10,613 y Sb=0,062.
- Coeficientes beta, que se obtienen estimando la regresión a partir de las observaciones estandarizadas. En la regresión simple este coeficiente coincide con el coeficiente de correlación lineal simple, r.
- Estadísticos t de los contrastes de significación de las estimaciones y sus correspondientes niveles de significación críticos:
=-12,511 y
=18,662. En este caso las estimaciones son significativamente distintas decero para cualquier nivel de significación.
Ejemplo 2.
Compruebe si existen valores extremos y analice el comportamiento de los residuos del modelo de regresión lineal estimado en el apartado anterior.
Con la secuencia Analizar > Regresión > Lineal aparece el correspondiente cuadro de diálogo en el que se mantienen seleccionadas la variable Peso como Dependiente y la variable Est como Independiente. Con el botón Estadísticos se accede al cuadro de diálogo que presenta las opciones correspondientes al diagnóstico de residuos. Se activa Diagnóstico por caso y Valores atípicos a más de 2 desviaciones típicas.


- Se observa que únicamente un caso presenta un resíduo estandarizado, igual a 2,046, superior a 2 veces la desviación estándar. Esto nos indica que no existe ningún caso atípico.
- En el cuadro Estadísticos sobre los residuos se comprueba que efectivamente no hay valores atípicos ya que los valores máximo y mínimo de los residuos tipificados son inferiores a 3 en valor absoluto.
Con el botón Gráficos se abre el cuadro de diálogo donde se deben activar las opciones correspondientes a los Gráficos de residuos tipificados.
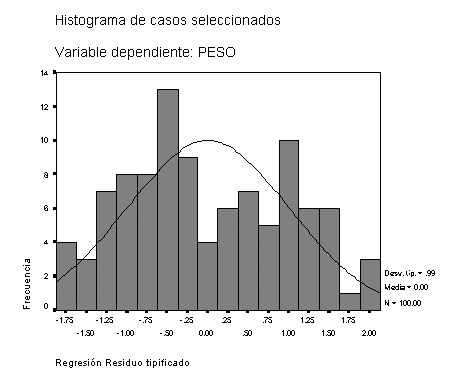
El histograma de los residuos permite comprobar gráficamente la hipótesis de normalidad; aspecto que deberá tenerse en cuenta para la interpretación de los resultados de la inferencia estadística. En este caso vemos que la distribución es campaniforme pero presenta una laguna en el centro que puede ser, en parte, consecuencia de los intervalos definidos.
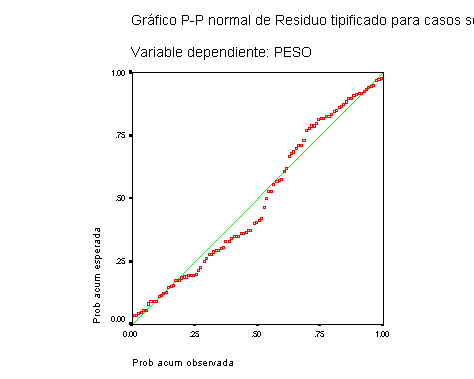
El diagrama P-P compara la frecuencia acumulada por los residuos tipificados con la probabilidad esperada bajo la hipótesis de normalidad. Se observa que estas diferencias podrían ser significativas en alguna zona del gráfico; lo cual, de ser cierto, pondría en duda la validez de la hipótesis de normalidad de los residuos. No obstante, el criterio para decidir si se puede rechazar la hipótesis de normalidad será el que proporcione alguno de los contrastes de normalidad.
Además, en el mismo cuadro de diálogo se puede pedir que elabore los diagramas de dispersión de, por ejemplo, los residuos estandarizados en función de la variable dependiente (ZRESID y DEPENDNT).

En el gráfico vemos que no existe ningún patrón de comportamiento de los residuos respecto a Y. Por lo tanto, podemos mantener que estas variables aleatorias están incorrelacionadas.
Ejemplo 3.
Obtenga las predicciones y los residuos correspondientes a los 100 casos incluidos en la estimación y a los 14 casos excluidos.
Con la secuencia Analizar > Regresión > Lineal aparece el correspondiente cuadro de diálogo en el que se mantienen seleccionadas la variable Peso como Dependiente y la variable Est como Independiente. Con el botón Guardar se abre el cuadro de diálogo donde se deben activar las opciones:
- Valores Pronosticados > No tipificados y Tipificados para obtener las predicciones a partir del modelo estimado.
- Residuos > No tipificados y Tipificados para obtener los residuos de todos los casos.
- Intervalos de Pronóstico > Media e Individuos para obtener los límites de los intervalos.
Los resultados de estas opciones quedan almacenados en el archivo de datos activo, y están disponibles para análisis posteriores. Por defecto los nombres de las variables que crea son: Pre_1 (predicciones no estandarizadas), Res_1 (residuos no estandarizados), Zpr_1, Zre_1(predicciones y residuos estandarizados, respectivamente), Sep_1 (error estándar de las predicciones), Imci_1, Unci_1 (Límite inferior y superior del intervalo de confianza para la predicción del valor esperado de Y), Lici_1, Uici_1 (Límite inferior y superior del intervalo de confianza para la predicción individual de Y).
Por ejemplo, para el caso 101, que presenta una estatura de 168 y un pesoigual a 56, los resultados son:
- Predicción del peso sin tipificar 60,04886 Kg. y tipificada -0,43094.
- Residuos, no tipificados y tipificados, -4,04886 y -0,66771, respectivamente.
- Error estándar de la predicción 0,66081.
- Intervalo de confianza para el valor esperado de Y para los individuos con estatura 168 (58,73751 ; 61,36022).
- Intervalo de confianza para el valor individual (47,94423 ; 72,15350).
Idénticamente, la predicción para el caso 102, que presenta una estatura de 180, es de 73,82255 kg., con un residuo igual a -3,82255 y un error estándar 0,77055. Los correspondientes intervalos de confianza para el valor esperado y para el valor individual son (72,29343 ; 75,35167) y (61,69239; 85,95271), respectivamente.
|
|