Sumari
1. Introducción
2. Características de la información estadística
2.1. Precisiones terminológicas
2.2. Características de los datos estadísticos: la importancia de los metadatos o contexto
2.3. Problemas de metodología
3. Los productores: fuentes o agencias estadísticas
3.1. El concepto de agencia o fuente estadística
3.2. Sistema estadístico en un país concreto: el caso de España
3.3. Sistema estadístico internacional
3.4. Rediseminación: el papel de las empresas privadas
4. El producto: como se elaboran y difunden las estadísticas
4.1. Circuito estadístico: como se elabora una estadística
4.2. Tipos de soportes y sistemas de difusión
4.3. El precio de los datos
5. Los usuarios
5.1. El concepto de alfabetización estadística (statistical literacy)
5.2. Identificar a los usuarios
5.3. ¿Qué quieren los usuarios?
6. ¿Cómo buscar?
6.1. ¿Dónde buscar?
6.2. Interfaces: problemas de diseño
6.3. Métodos de búsqueda
6.4. Metadatos estadísticos
7. Datos agregados en las bibliotecas
7.1. ¿Qué datos para qué bibliotecas?
7.2. ¿Qué datos se deben comprar?
7.3. ¿Cómo difundir la información y atender a los usuarios?
8. Microdatos en las bibliotecas
8.1. Datos base en las bibliotecas
8.2. El problema del secreto estadístico
8.3. Gratuidad, pago y archivos de datos sociales
9. La investigación documental
10. Conclusiones
11. Bibliografía
Resumen [Abstract][Resum]
Se presenta el estado de la cuestión de las fuentes de información estadística y el papel que las bibliotecas pueden jugar en su difusión. Este sector está inmerso en un cambio acelerado fruto de los nuevos soportes digitales y de Internet, aunque simultáneamente sufre a baja alfabetización estadística de la mayoría de los usuarios potenciales. En primer lugar se hace una introducción a la información estadística: características metodológicas; productores (fuentes y agencias); circuitos de creación y distribución, necesidades de los usuarios, estrategias de búsqueda e interfaces. En segundo lugar, se evalúa el papel de las bibliotecas en la compra, gestión y difusión de este tipo de material, desde la referencia básica hasta la alta investigación.
1 Introducción
“Hay mentiras, grandes mentiras y estadísticas.”
Cita atribuida a Benjamin Disraeli, primer ministro inglés del s. XIXLa documentación ha dedicado poca atención a las estadísticas como fuente o tipo de información, como mínimo en comparación con los estudios dedicados a la información textual o audiovisual. Es mucho más fácil encontrar literatura profesional dedicada a las estadísticas como método de evaluación, de gestión o de investigación.
La información estadística tiene mala prensa. Como muestra, la cita que encabeza esta introducción y muchas otras en la misma línea.1 Esto es irónico, ya que los métodos cuantitativos aspiran a mostrar la realidad de la forma más exacta y objetiva posible. Los motivos de esta desconfianza son múltiples, pero uno de los más importantes es la deficiente alfabetización matemática de la mayor parte de la población.
El problema es que Internet ha implicado una democratización casi total de la información estadística. Hace sólo una década, la mayoría de las bases de datos numéricas sólo eran accesibles a especialistas. Actualmente, en cambio, la mayoría son accesibles a cualquier persona con una conexión a Internet. Por lo tanto tenemos una contradicción aparente: un acceso muy abierto a una información que no siempre se entiende.
En este contexto, ¿cuál es el papel de las bibliotecas? Este artículo intenta responder a esta pregunta y al mismo tiempo ofrecer una introducción a los procesos, circuitos de difusión, agencias productoras, etc. de los datos estadísticos. En resumen, se pretende ofrecer un estado de la cuestión en un momento de profundo cambio.
Este artículo se basa en diversos trabajos llevados a cabo por el primer año del programa de doctorado “Informació i Documentació en l’Era Digital” (Universitat de Barcelona) durante el curso 2003–04, así como en la experiencia profesional acumulada en la Biblioteca de la Universitat Pompeu Fabra (UPF).
Antes de finalizar esta introducción, es necesario agradecer la colaboración y ayuda de diferentes personas: Elena Blanco (bibliotecaria de la UPF, també especializada en datos estadísticos), Gemma Estrugas (bibliotecaria de la Unitat d’Estadístiques de la Universitat Autónoma de Barcelona) y Roser Riera (bibliotecaria del Institut d’Estadística de Catalunya). Y muy especialmente al profesorado (y alumnado) de la UPF que, al exponer sus necesidades de información, también me ha enseñado todo lo que era necesario saber sobre este mundo: Maia Güell, Javier Ramos, Francesc Pallarès, Walter García y un largo etcétera.
2 Características de la información estadística
2.1 Precisiones terminológicas
“Experts need specialized terminology, but terminology can also serve as a barrier to finding or understanding the information”2 Es importante en cualquier trabajo definir, de entrada, el objeto de estudio y la terminología que se va a utilizar. Aún más en este caso, ya que la terminología no es muy clara y abunda en palabras directamente traducidas del inglés.3 En primer lugar, el término datos (en inglés data) es muy común, pero también es ambiguo. Datos significa simplemente ‘hechos’ por contraposición a ‘interpretación’ u ‘opiniones’, y también para diferenciarlo de conceptos como información o conocimiento. Pero en muchos textos, especialmente los escritos en inglés, acaba siendo sinónimo de datos estadísticos. En este sentido, podemos encontrarlo en multitud de términos compuestos ingleses: data file, data archive, social data, etc., que se traducen al español como fichero de datos, archivo de datos y datos sociales.4
Datos estadísticos sería pues el término más correcto y el que se utilizará en este artículo de forma habitual. Según la definición del Diccionario de la lengua española, de la Real Academia,5 la estadística es el “estudio de los datos cuantitativos de la población, de los recursos naturales e industriales, del tráfico o de cualquier otra manifestación de las sociedades humanas”. Se trata de un término genérico y que se utiliza en el lenguaje corriente. Pero estrictamente hablando, sólo serían “estadísticas” los datos tratados con métodos precisamente estadísticos. Debido a esto, en el contexto anglosajón también se utiliza la expresión datos numéricos (en inglés numeric/al data). En teoría los dos términos no son exactamente sinónimos, ya que numéricos sería un poco más amplio que estadísticos. Pero se utilizan de manera bastante indistinta.
Utilizaremos el término base de datos estadística para las bases de datos de este tipo de información. En inglés se utiliza mucho data bank, por contraposición a data base. Data bank o banco de datos sería para las bases de datos no bibliográficas, y especialmente las estadísticas. Pero es un término un poco ambiguo, así que base de datos estadística/numérica resulta mejor. Fichero de datos (en inglés dataset o datafile) designaría, en cambio, un fichero informático que contiene información estadística pero no incluye un software de recuperación.
A lo largo del artículo y a medida que se considere necesario se irán definiendo otros términos especializados.
2.2 Características de los datos estadísticos: la importancia de los metadatos o contexto
“Without metadata, a number has no meaning”6
“Statistics are highly compressed forms of information. Standing alone, as individual numbers, they have little meaning. It is only within the context of their place in a particular table that meaning is provided. Column and row names provide important information about the meaning of the number. Additionally, one must know the units of measurement, the methods by which the data were collected and analyzed, and sometimes a particular number’s relationship to others (such as in a time-series).”7La información numérica es tan omnipresente en la sociedad que se acostumbra a olvidar que es muy diferente de la información textual. Tiene características y dinámicas propias que determinan desde los métodos de búsqueda hasta las necesidades de los usuarios.
La característica principal que define los datos estadísticos es su dependencia del contexto o metadatos. Imaginemos que tenemos esta cifra: 1,29. ¿Qué quiere decir por sí misma? Absolutamente nada. En cambio, si va acompañada de la frase “promedio de hijos por mujer en España en el 2003”, de repente adquiere un significado. Este “contexto” de la información numérica normalmente se estructura en tres o cuatro variables, que serían: a) tema, b) lugar, c) tiempo y d) unidad.
Por ejemplo:
Tema Lugar Tiempo Unidad 1,29 Fertilidad España 2003 Promedio de hijos / mujer 23,090 PIB por cápita Francia 1998 Dólares “internacionales” 76 Área forestal Finlandia 1995 Tanto por ciento (%)
Si cambiamos cualquiera de las variables, obtenemos una cifra distinta. Si tenemos diversas cifras correspondientes a diferentes años (o meses, trimestres, etc.), disponemos de una serie temporal o serie estadística. Además, raramente una cifra es significativa por sí sola. Si decimos que el PIB español ha crecido un 2,4 % en 2004, ¿esto es poco o mucho? Es un poco más que en 2001 (2,8 %), pero mucho más que en 2000 (2 %). Y también lo podemos comparar geográficamente: este 2,4 % de crecimiento en España es mucho más alto que en Italia (1,1 %), pero más bajo que en Estados Unidos (4 %) para el mismo año.
2.3 Problemas de metodología
Para poder evaluar correctamente un dato estadístico es vital conocer la metodología que se ha utilizado en su elaboración, lo cual implica también buenos conocimientos de terminología. Por ejemplo, ¿cuántas personas conocen qué es y cómo se calcula el PIB? ¿Y qué diferencia hay con el PNB? ¿O cómo se calcula el IPC? Sin embargo, la mayoría de la población confía en estas cifras.
Debido a que las estadísticas sirven básicamente para hacer comparaciones, es vital que los datos sean metodológicamente comparables. Por ejemplo, si encontramos que el paro en 2004 en el Reino Unido (4,7) es mucho más bajo que en Francia (9,7), debemos asegurarnos que estamos hablando de lo mismo. Si el Reino Unido y Francia cuentan los parados de forma distinta, difícilmente se podrá sacar alguna conclusión. En la estadística oficial (la que recopila la administración pública) se puede decir que no hay muchos problemas de metodología. Las cifras se recopilan de manera similar gracias a sistemas, protocolos y acuerdos de alcance internacional. Por ejemplo, en el caso del paro, según las normas de la Oficina Internacional del Trabajo (OIT). También se procura que las clasificaciones utilizadas sean equivalentes entre sí, como por ejemplo la clasificación de actividades económicas de la ONU (ISIC, http://unstats.un.org/unsd/cr/registry/regcst.asp?Cl=27&Lg=1) respecto a la NACE europea (http://europa.eu.int/comm/eurostat/ramon/) y la Clasificación nacional de actividades económicas (CNAE, http://www.ine.es/inebase/cgi/um?M=/t40/cnae93rev1/&O=inebase&N=&L=0) española.
Es necesario tener en cuenta que pueden existir varios métodos para cuantificar la misma cosa. Así, por ejemplo, no suele ser lo mismo el paro registrado y el que se deduce de las encuestas de trabajo o población activa. En el primer caso, es un número bastante exacto que sólo recoge los parados que están registrados en una oficina de colocación o entidad similar. En el segundo, se trata de una encuesta que se lleva a cabo sobre una muestra de ciudadanos y que permite que afloren las personas sin trabajo, pero que posiblemente no estén inscritas en ninguna oficina. Este es el típico caso que desconcierta a una persona sin conocimientos de metodología.
También existe la cuestión de la terminología puramente matemática. Así, una misma cifra se puede presentar de diversas formas: total, tasa, tanto por cien, promedio, número índice. Una unidad tan simple como es la moneda nacional de un país se puede expresar en números corrientes o constantes, según se tenga en cuenta o no la inflación acumulada.
En un mundo ideal, los usuarios deberían tener unos conocimientos mínimos sobre estas cuestiones. Pero el mundo real no es así, y quizás una de las funciones de la biblioteca es dirigir a los usuarios hacia la fuente estadística adecuada a su nivel de conocimientos. Ejemplo: una base de datos económica mínimamente compleja puede presentar el PIB calculado de tres o cuatro formas distintas. Pero un usuario que sólo quiera llevar a cabo una comparación entre países preferirá una fuente en la que estos datos se presenten en dólares y de una forma simple.
3 Los productores: fuentes o agencias estadísticas
3.1 El concepto de agencia o fuente estadística
La producción de estadísticas es un proceso que se no se parece al circuito editorial habitual. En lugar de autores o editoriales, se basa en la agencia o fuente estadística (en inglés statistical source/agency). ¿Qué es una fuente o agencia estadística? Se trata de una entidad que recopila, procesa y distribuye datos estadísticos. Se puede tratar de entidades oficiales plenamente dedicadas a esta función —Eurostat, Instituto Nacional de Estadística (INE), Centro de Investigaciones Sociológicas (CIS), etc.—, entidades oficiales que producen estadísticas aunque esta no sea su actividad principal (Organización de Cooperación y Desarrollo Económicos —OCDE—, ONU, etc.), o bien entidades privadas (asociaciones profesionales, empresas de marketing, etc.). Fuente estadística es, hasta cierto punto, sinónimo de agencia estadística, aunque agència se suele aplicar más restrictivamente a las fuentes oficiales.8
El concepto de agència o fuente es importante, ya que es la base de todo el sistema. Cuando se cita o se reproduce una estadística (por ejemplo, para acompañar el texto de un artículo o un libro), se suele citar como fuente la entidad que la ha producido, y, además, de forma más secundaria, el título de la publicación o base de datos de donde se ha extraído la información. La cita de la fuente permite juzgar la fiabilidad de los datos y facilita al usuario la tarea de comprobarlos o actualizarlos.
3.2 Sistema estadístico en un país concreto: el caso de España
Existen fuentes oficiales y fuentes no oficiales, fuentes de ámbito internacional, nacional y local, y fuentes generales y fuentes temáticas. Pero las estadísticas más conocidas son las producidas por los sistemas estadísticos oficiales de cada país. Este sistema se gestiona por y para la Administración, y su función principal no es ofrecer información al público en general, sino proporcionar al gobierno (en un sentido amplio) los datos que necesita para crear y poner en marcha políticas públicas. ¿De donde se extrae esta información? Lo veremos con más profundidad en el apartado siguiente, pero la inmensa mayoría de los datos tienen su origen en los procesos administrativos. Cuando éstos son insuficientes, se utilizan encuestas. Todo el sistema se regula por medio de leyes, organigramas y programas a largo plazo. Así se sabe qué datos se han de recopilar, con qué metodología y qué entidad debe hacerlo. Es necesario que sea así a causa de la complejidad extrema de todo el procedimiento. El reverso negativo de la moneda es la rigidez y burocratización de los sistemas estadísticos oficiales.
La pieza central del sistema es la agencia estadística central de cada país, en nuestro caso el Instituto Nacional de Estadística de España (INE, http://www.ine.es/).9 El INE es la agencia de la administración central dedicada exclusivamente a recopilar, gestionar y difundir datos estadísticos. También es el enlace de España (estadísticamente hablando) con otras agencias similares pero de ámbito supranacional o internacional. No es la única entidad oficial que recopila estadísticas. Esta tarea está repartida por toda la administración según Inventario de Operaciones Estadísticas de la Administración Central del Estado (IOE, http://www.ine.es/ioe/ioeOrg.jsp?cod=00000000&L=0). Pero el INE es quien coordina todo el sistema y también es el punto central de difusión. Así, su base de datos INEBase incluye datos provenientes de todo el IOE. Sin embargo, las diversas entidades pueden difundir sus estadísticas por su cuenta y a veces con un nivel de detalle más elevado que no el INE.
Al igual que existen diferentes niveles de la administración (estatal, autonómica y local), existen diferentes niveles de estadísticas oficiales. El INE recopila datos a diferentes niveles de “desagregación territorial”: nacional, autonómico, provincial, local. Pero también delega algunas funciones en las agencias estadísticas autonómicas, a las cuales también coordina. Actualmente se puede decir que casi todas las comunidades autonómicas tienen una. Estas agencias llevan a cabo una tarea importante al ofrecer estudios especializados y datos a un nivel de desagregación más detallado que no el INE. Un ejemplo sería el Institut d’Estadística de Catalunya (IDESCAT, http://www.idescat.net/). Para finalizar, las administraciones locales son también importantes. Por ejemplo, el padrón es responsabilidad de los ayuntamientos. Ahora bien, sólo los ayuntamientos más importantes se pueden permitir disponer de un departamento de estadística o de una unidad similar propias, como por ejemplo el Departament d’Estadística del Ayuntamiento de Barcelona (http://www.bcn.es/estadistica/catala/index.htm).
En un ámbito ligeramente diferente, encontramos el Centro de Investigaciones Sociológicas (CIS, http://www.cis.es/), que es la entidad oficial encargada de llevar a cabo, archivar y difundir encuestas de opinión y estudios similares. Su sitio web define esta misión como el estudio científico de la sociedad española. Este tipo de entidad se denomina también archivo de datos (en inglés data archive). Se trata de un servicio que archiva y permite buscar, difundir y acceder a datos estadísticos de tipo social, especialmente encuestas. Una agencia estadística también puede ser un archivo de datos, pero el término se aplica más bien a centros que recopilan datos procedentes de diversas fuentes. En España, el CIS depende de la Administración, en concreto del Ministerio de la Presidencia; en otros países estos archivos suelen estar vinculados a universidades o centros de investigación.
Sin embargo, existen muchas estadísticas que quedan fuera del sistema oficial. Sea porque el Estado no dispone de las herramientas para recopilarlas, sea porque tampoco existe mucho interés por hacerlo. Existen varios niveles en la estadística no oficial: a) entidades privadas pero sin ánimo de lucro que llevan a cabo o financian encuestas sociales; b) asociaciones sectoriales y/o profesionales que se encargan de recoger datos dentro de su ámbito de actuación; c) datos que las empresas generan como parte de su negocio, como por ejemplo las cuentas anuales, y d) datos generados por empresas que se dedican precisamente a recopilar y procesar datos numéricos, como por ejemplo las de márqueting.10
3.3 Sistema estadístico internacional
El instituto estadístico oficial de cada país transmite los datos a las agencias internacionales de las cuales el país forme parte. Pueden ser instituciones regionales (en el sentido de agrupar distintos países sobre una base geográfica o cultural, como por ejemplo la Unión Europea o el Asian Development Bank) o internacionales (como por ejemplo las Naciones Unidas). Pueden encargarse de todo tipo de datos o sólo los un tema concreto. Estas agencias no recopilan los datos, ya que los sistemas estadísticos nacionales se los proporcionan. Lo que sí hacen es armonizarlos, es decir, tratarlos para que sean comparables. Hecho esto, los difunden y ofrecen así fuentes estadísticas excelentes para la comparación internacional.
En nuestro contexto, la agencia de este tipo más importante es Eurostat http://epp.eurostat.cec.eu.int/), el instituto estadístico de la Unión Europea. Por encima de Eurostat no se puede decir que haya ninguna “agencia estadística mundial”, aunque la División Estadística de las Naciones Unidas (http://unstats.un.org/unsd/) se aproxime bastante. Existen también diferentes asociaciones regionales (por ejemplo, la OCDE) y una larga nómina de entidades sectoriales —como por ejemplo el Fondo Monetario Internacional (FMI), la Organización Mundial del Comercio (OMC), la Unesco, la Organización Internacional del Trabajo (OIT), etc., que recopilan y difunden datos estadísticos dentro de su ámbito de actuación.
3.4 Rediseminación: el papel de las empresas privadas
En este contexto, ¿existen empresas que comercialicen estadísticas pero que no las produzcan? No son numerosas pero haberla haylas, y se dedican fundamentalmente a dos funciones. La primera es la rediseminación: comprar datos a las agencias oficiales y revenderlos. Normalmente esto implica comprar datos a diferentes agencias y/o aplicar un software de recuperación que permita una búsqueda mejorada y conjunta.11 La segunda función es recopilar datos estadísticos muy detallados del sector privado que las agencias oficiales no gestionan. Por ejemplo, los datos financieros, bursátiles y de cuentas de empresas (un ejemplo en el ámbito español sería el SABI: Sistema de análisis de balances ibéricos).
En muchos casos ambas funciones se combinan. Se ofrece un producto que incluya datos numéricos privados y públicos, juntamente con un software de recuperación complejo (por ejemplo, las bases de datos Datastream o Compustat) y un buen sistema de actualización. Las bases de datos resultantes suelen ser muy caras, debido a dos factores. En primer lugar, crear y, especialmente, mantener estas bases de datos requiere una inversión enorme y el precio está, lógicamente a la altura. El segundo factor se deriva del primero: estas empresas no tienen mucha competencia. Además, la mayoría de sus clientes (analistas financieros, bancos e instituciones financieras, grandes empresas, etc.) se lo pueden permitir.
4. El producto: com se elaboran y difunden las estadísticas
4.1 Circuito estadístico: cómo se elabora una estadística
La elaboración de una estadística pasa por tres fases: la recopilación de los datos, su procesamiento y la difusión del resultado final.
Recopilación de los datos
Los datos base de la estadística oficial se recopilan mediante dos métodos: procedimientos administrativos y encuestas por muestra. En el primer caso se puede decir que se recopilan gracias a las relaciones que una persona, física o jurídica, mantiene con la administración pública. Ejemplos de esto son los registros (nacimiento, matrimonios, defunciones, entidades, etc.), los pagos de impuestos, los derechos de aduanas, las altas y las bajas hospitalarias, etc.
Pero existen muchos datos que no se pueden recopilar por esta vía, y entonces las agencias oficiales recurren a encuestas. Una encuesta consiste en un cuestionario con una serie más o menos larga de preguntas que se formulan a personas o entidades. Existe un tipo de encuesta en la que se pregunta a todos los habitantes del país: el censo. Es la encuesta más completa posible y también el “retrato” estadístico más fiable de una sociedad. Pero organizarla y tratarla es tan complejo que solamente se realiza cada diez años. Por este motivo el resto de encuestas se realizan sobre una muestra de la población. Se eligen una serie de personas que representan, a escala, el total, y después los resultados se extrapolan. La situación ideal (como mínimo desde el punto de vista de los investigadores sociales) es que estas encuestas sean longitudinales, es decir, que se repita la misma encuesta a la misma muestra de personas o a una similar a intervalos regulares.
Evidentemente, las entidades privadas que también elaboran datos estadísticos no tienen los recursos administrativos del Estado. En algunos casos pueden recoger algunos datos de forma bastante automática (cuentas de empresa, altas y bajas, etc.), pero en muchos otros casos los datos de las mismas provienen de encuestas.
Procesamiento de los datos: datos no agregados o microdatos
A los datos base se les aplican diversos métodos estadísticos para crear los datos finales. Pero el proceso que explicaremos aquí detalladamente es el que se sigue en el caso de las encuestas, ya que los ficheros resultantes tienen mucha importancia para los investigadores sociales. Los datos que se recogen mediante las encuestas se transfieren a ficheros de datos denominados microdatos (en inglés microdata). Los microdatos son ficheros donde se recopilan las respuestas individuales de cada persona entrevistada, pero codificadas de forma numérica. En bruto tienen el aspecto de largas series numéricas:
100108622061123100000000570430110000
100108622060000000000000000000000000
100108622060444242000200414444490134
100108622060022222212212222222222222
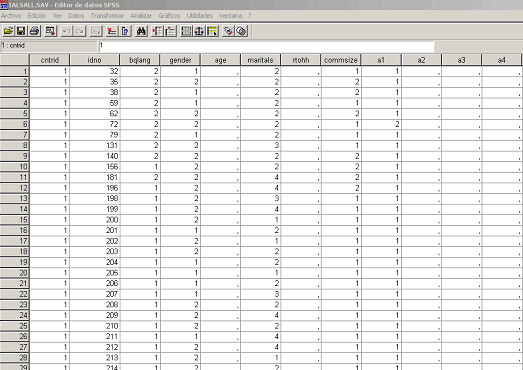
Abiertos con un software estadístico, el resultado es una tabla donde cada fila es una persona, y cada columna corresponde a una pregunta. La respuesta está codificada numéricamente. Por ejemplo, el género del entrevistado: hombre = 1 y mujer = 2.
Figura 1. Fichero de microdatos visualizado con el programa SPSS.
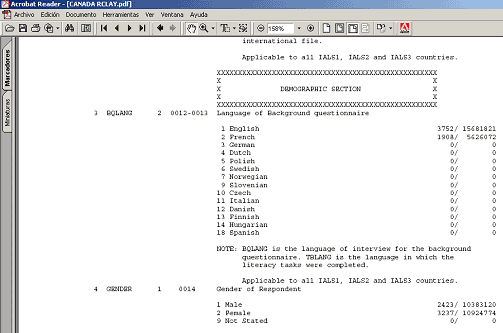
Por lo tanto, para poder interpretar el fichero necesitamos el libro de códigos o cuestionario, donde constan las preguntas y la codificación de las respuestas.
Figura 2. Cuestionario de un fichero de microdatos.
Estos ficheros no son muy conocidos por el público general, pero tienen gran interés para muchos investigadores, ya que permiten llevar a cabo investigación social avanzada. Las agencias lo saben y los ofrecen bajo ciertas restricciones debido a la confidencialidad de los datos personales.
Resultado final: datos agregados o estadísticos
Sobre la base de estos ficheros de microdatos o de registros administrativos, las agencias como por ejemplo el INE generan los resultados agregados, que es lo que normalmente se conoce por datos estadísticos. El término resultado agregado, muy técnico, indica que los valores se han agregado de acuerdo con ciertas unidades colectivas o grupos. Por ejemplo, para conocer el paro femenino se agregan todas las respuestas individuales que están codificadas como personas del sexo femenino. Se pueden agrupar bajo múltiples variables: por ejemplo, mujeres casadas, con hijos menores de edad, en paro y con residencia en Cataluña. Los resultados se introducen en una base de datos y ya se pueden difundir mediante diversos canales que veremos con más detalle en el apartado siguiente.
4.2 Tipos de soportes y sistemas de difusión
“Un estudiante de secundaria tiene hoy un mejor acceso a datos estadísticos básicos que no un alto funcionario hace sólo cinco años.” (Katze, 1997)12 El proceso de difusión de las estadísticas ha cambiado muchísimo entre los últimos diez y veinte años y, de hecho, quizás es uno de los sectores que ha pasado más rápida y radicalmente a los nuevos soportes digitales, primero, y después a Internet. La difusión tradicional se basaba en la publicación en papel de revistas y monografías, la más típica de las cuales era el anuario estadístico. Estas publicaciones se continúan editando, pero ya no son el método de difusión principal.
El primer avance fue la informatización de las agencias, lo que permitió la consulta a los investigadores, sea in situ —en la misma agencia— o por medio de una teledocumentación primitiva. La segunda revolución fue la de los disquetes y CD-ROM. Esto permitió la consulta de las bases de datos o de una parte de ellas fuera de las agencias estadísticas. Estos soportes electrónicos empezaron a acompañar a las publicaciones como material de acompañamiento, y en algunos casos los sustituían directamente.
Pero la revolución definitiva ha sido Internet. Actualmente, desde cualquier ordenador se puede consultar la estadística de cualquier país o tema, aunque el servidor de la agencia esté en la otra punta del mundo. Sólo hace falta, evidentemente, que la agencia estadística facilite el acceso por medio de su web. De manera muy rápida, un tipo de información que hasta hace poco estaba limitada a especialistas se ha puesto al alcance del público en general.
El principal problema de los usuarios ha cambiado: los datos son ahora accesibles, pero la estructura y la búsqueda de estas bases de datos no siempre es fácil. En otras palabras, muchas veces el usuario puede conseguir la información, pero o bien es difícil de localizar dentro de las bases de datos o bien es de difícil interpretación. Es en este campo que se concentran la mayoría de los esfuerzos de la investigación documental.13
4.3 El precio de los datos
“Because the public has already paid for the information through taxes, it is argued that information should be made available at merely the reproduction cost”14 ¿Estos datos ofrecidos por Internet son siempre de libre acceso? Depende de la agencia. La situación se podría resumir diciendo que las agencias oficiales nacionales suelen ofrecer los datos en libre acceso; las agencias internacionales, en acceso libre o a precio político, y las privadas, a un precio elevado. Evidentemente es una simplificación excesiva que oculta disparidades, pero en líneas generales esta es la tónica.
La mayoría de agencias oficiales proporcionan, como mínimo, una parte de los datos en libre acceso vía Internet. Lo que constituye, de hecho, una derivación de la etapa anterior, cuando las publicaciones en papel o CD-ROM ya solían tener normalmente un precio “político” muy bajo o incluso se distribuían gratuitamente a universidades y bibliotecas. La justificación es que estos datos se han recopilado y tratado con dinero del contribuyente y, por lo tanto, éste tiene derecho a poder consultarlos a un coste mínimo. Esta idea, muy arraigada en los países de tradición anglosajona, se ha ido extendiendo progresivamente. Actualmente, en España los datos estadísticos oficiales son de libre acceso en la mayoría de los casos. En el caso de la Unión Europea (Eurostat) fueron de pago hasta octubre de 2004, pero ahora son ya gratuitos. En resumen, es cada agencia nacional la que fija la política correspondiente, pero en general se tiende a la gratuidad.
El caso de los microdatos es diferente. Algunas agencias los ofrecen gratuitamente (como el INE desde junio de 2004), o bien a precios razonables (como el CIS), o bien a precios muy elevados (el caso de Eurostat). También son datos públicos, pero se considera que sólo interesan a un sector muy pequeño de usuarios (investigadores) y, por lo tanto, la idea de servicio público no es tan evidente. Además, tienen problemas de protección de datos personales que hacen preferible en muchos casos una difusión controlada.
Por lo que respecta a las agencias supranacionales o internacionales, la tendencia parece ser el libre acceso, sobretodo para los datos más básicos. Si los datos son de pago, el precio suele ser político, limitado a recuperar costes y con importantes descuentos “sociales” (universidades, instituciones sin ánimo de lucro, países del tercer mundo, etc.).
Muy diferente es el caso de las bases de datos de titularidad privada. El tipo de información (financiera o económica) y sus clientes habituales (bancos, instituciones financieras, analistas de bolsa) implican en general precios muy caros. Las instituciones docentes pueden intentar conseguir descuentos, pero no siempre es posible.
5 Los usuarios
“The challenge is to provide and share data on demand, internally and externally to power users, experts and decision makers; whilst ensuring access to information for novice users and a wider audience that will often include the general public”15 5.1 El concepto de alfabetización estadística (statistical literacy)
Durante los últimos años se ha popularizado el término alfabetización informacional, traducido directamente del inglés information literacy. En la misma línea, muchos especialistas hablan de alfabetización estadística (también denominada matemática o cuantitativa). Cada vez el acceso a los datos numéricos es más simple, pero en cambio muchos usuarios no saben realmente cómo plantear las búsquedas en las bases de datos, ni la metodología que hay detrás, ni cómo evaluar su fiabilidad, etc.
Las carencias se encuentran en tres grandes áreas:
a) Una base matemática muy deficiente en amplios sectores de la población.16
b) Problemas de terminología, principalmente económica. Así, muchos usuarios no saben realmente qué es el PIB, el PNB o el PPP. Tampoco conocen los equivalentes ingleses, cuando el inglés es el idioma de búsqueda de la mayoría de bases de datos estadísticas.
c) Conocimientos de metodología. Dicho de otra manera, los usuarios no saben cómo se recopilan y calculan las estadísticas y, por lo tanto, no tienen en realidad herramientas para criticarlas.
Es un problema grave que retroalimenta la “mala fama” que tiene este tipo de información. Por ejemplo, si el usuario no sabe que existen dos formas muy diferentes de recoger los datos sobre el paro (el registrado o por encuesta de población activa), quedará muy desconcertado al encontrar dos cifras distintas. El problema empeora cuando los medios de comunicación publican resultados de forma confusa o los políticos los utilizan como arma dialéctica. Existe un refrán “estadístico” para este tipo de uso: “He uses statistics as a drunken man uses lampposts —for support rather than for illumination”.17
Debido a la alarma de los expertos, han surgido algunas iniciativas muy interesantes. Así se multiplican los libros y sitios web que intentar hacer de la estadística una materia, si no entretenida, como mínimo un poco más digerible. En la misma línea o similar, diversas iniciativas exponen las “mentiras estadísticas” de los medios o los políticos, con explicaciones detalladas y una necesaria dosis de humor. Y diferentes proyectos y publicaciones intentan ayudar al profesorado en la difícil tarea de la docencia estadística.18 Para variar, los esfuerzos provienen casi exclusivamente de los países anglosajones.19
5.2 Identificar a los usuarios
“There is a varied and unpredictable demand for European data”20 Las estadísticas no son una materia, sino una manera de presentar la información. Desde este punto de vista, la identificación de los usuarios es imposible. Evidentemente, los datos estadísticos están más asociados a ciertas áreas de conocimiento: economía, sociología, administración, etc. Pero se puede encontrar información estadística de cualquier tema: ocio y espectáculos, medicina, medio ambiente, justicia, etc.
A pesar de todo, algunos estudios han intentado clasificar a los usuarios de las estadísticas oficiales. Sirva como ejemplo el trabajo de Hert/Marchionini,21 que analizó el uso de diversas webs estadísticas norteamericanas. A grandes rasgos, se identificaron ocho tipologías:
- Sector privado: usuarios de empresas privadas que necesitan datos para su negocio.
- Universidades: investigadores, estudiantes universitarios y personal en general.
- Medios de comunicación: periodistas.
- Público en general: usuarios que buscan datos por razones privadas y no de trabajo.
- Gobierno: funcionarios y políticos, por razones de administración y política pública.
- Educación: profesorado y alumnado no universitario.
- Estadística: especialistas en el tema.
- Bibliotecas, museos y otras entidades sin ánimo de lucro.
Otra forma de clasificar a los usuarios consiste en identificar los niveles de demanda. Porque no es lo mismo un alumno de secundaria sin conocimientos de estadística que un investigador universitario especialista en matemática. Identificar el nivel de complejidad permitirá también seleccionar el tipo de fuente estadística más adecuada para cada uno:
- Demanda concreta y/o básica: realizada por un usuario que no es especialista y que generalmente sólo pide unos datos básicos y fácilmente comprensibles. Muchas webs de agencias estadísticas suelen tener una sección de novedades, datos básicos, notas de prensa, etc., destinada a este tipo de demandas. En muchos casos un anuario, un artículo o un manual que incluya datos estadísticos será de más utilidad que una base de datos compleja. También se prefieren las unidades simples y fácilmente comparables. Por ejemplo, si se quiere comparar el PIB por cápita de distintos países, es preferible que todo esté en dólares.
- Demanda de nivel medio: realizada por un usuario con unos conocimientos matemáticos y/o de metodología mínimos. Es la típica demanda por motivos de docencia (profesorado) y aprendizaje (alumnado) en el ámbito universitario. Los primeros quieren encontrar datos que puedan utilizar en sus clases. Los segundos, datos para completar trabajos. Muchos otros tipos de usuarios, desde periodistas a médicos, también pueden necesitar datos en este nivel. En este caso, las mejores fuentes son las bases de datos “estándar” —ya sean de pago, o de libre acceso— de las agencias estadísticas oficiales.
- Demanda de investigación: realizada por un usuario especializado y con buenos conocimientos matemáticos y/o de metodología. Es el nivel más alto. Puede ser investigación universitaria, pero también estudios a fondo sobre políticas públicas de la Administración o bien estudios de marketing del sector privado. Se necesitan bases de datos complejas y también es el tipo de usuario que realiza un uso intensivo de los ficheros de microdatos.
5.3 ¿Qué quieren los usuarios?
No existen muchos estudios sobre qué quieren realmente los usuarios. Esta falta de investigación se debe a diversos factores. La dispersión de los posibles usuarios y las diferencias abismales de nivel hacen que sea difícil encontrar un sistema que funcione bien para todos. Además, hace relativamente pocos años que esta información es accesible, por lo que tampoco ha habido tiempo suficiente para realizar estudios. La mayoría de los que existen se han llevado a cabo en países anglosajones. Por ejemplo, los de Hyland y Gould (1998), Hert y Marchionini (1998), Blakemore y McKeever (2001), Marchionini (2002), Denn y Haas (2003), etc.
En general, los deseos de los usuarios se pueden clasificar en dos grandes grupos: los que se refieren a datos en sí y los referentes al acceso a éstos.
Demandas de los usuarios referentes a los datos en sí
- Actualización de los datos: los usuarios desean una actualización lo más rápida posible. Es una demanda razonable a primera vista, pero no siempre es posible. Los datos siguen un proceso de elaboración complejo. Entre que se recopilan, se procesan y se difunden pasa cierto tiempo. Si se trata de una entidad supranacional, hay un período suplementario hasta que son enviadas por las agencias nacionales y es posible que no exista la misma actualización para todos los países.
- Nivel de desagregación geográfica: muchos usuarios se quejan de que los datos son buenos en el ámbito nacional y en los primeros ámbitos administrativos, pero más deficientes en el ámbito local. La queja tiene parte de razón, pero también hay que tener en cuenta que muchos datos se recogen mediante encuestas de ámbito nacional. Esto quiere decir que se selecciona una muestra significativa y después se extrapolan los resultados a todo el país. Pero, evidentemente, no se pueden extrapolar los resultados en el caso de unidades geográficas reducidas. De esta forma, para según qué temas, sólo se tienen datos cada diez años, cuando se realizan censos completos a todos los habitantes.
- Cobertura cronológica: los usuarios no quieren solamente datos bien actualizados, sino también datos con la mayor antigüedad posible. Este tema se está solucionando lentamente, a medida que las agencias informatizan los fondos más antiguos. El problema es que, cuando los datos no están informatizados, la alternativa es directamente el soporte papel. Y los usuarios odian el soporte en papel, ya que implica tener de recopiar los datos con peligros evidentes de trascripción. Otra demanda habitual es una mejor periodicidad de los datos.
- Problemas con algunas materias: teóricamente puede haber datos de cualquier tema, pero también existen problemas. Especialmente:
- Temáticas de las cuales no es posible recoger datos de forma oficial, pero tampoco no es muy factible recurrir a encuestas. Por ejemplo, el número mínimamente exacto de inmigrantes ilegales. En otros casos puede haber graves divergencias entre las cifras administrativas y las que se recogen sobre la base de encuestas, hecho que desconcierta a los usuarios.
- Temas “nuevos”, debido a que pasa cierto tiempo entre que se detecta el fenómeno y el inicio de la recogida de datos correspondiente. Dos ejemplos: la incidencia del sida o la “nueva” economía de Internet.
- Temas de los cuales se recopilan datos pero no con el nivel de detalle que querría el usuario.
- Documentación de los datos: los usuarios la quieren completa y fácilmente accesible. Se trata de los manuales, cuestionarios, libros de códigos, etc. que explican la metodología utilizada para recoger y procesar los datos y muy especialmente los microdatos. Sin el listado de preguntas y los códigos de las respuestas, los microdatos no sirven para nada. Es sobre esta documentación adjunta que se están concentrando los esfuerzos para crear un sistema de metadatos estadísticos a nivel internacional.
Demandas de los usuarios referentes al acceso a los datos
- Acceso libre/gratuito: es uno de los efectos de Internet, que ha acostumbrado a muchos usuarios a la gratuidad total. Es una demanda razonable a ciertos niveles. Por ejemplo, los datos nacionales son generalmente de libre acceso (una tendencia en aumento), pero esto se debe a la filosofía de servicio público de estas agencias. Pero cuando se trata de datos de agencias supranacionales o privadas, la cosa ya no está tan clara. Muchas agencias internacionales difunden los datos de forma gratuita, pero algunas tienen problemas presupuestarios evidentes (pensemos en la ONU) y no se pueden permitir la gratuidad total cuando esta tarea les comporta gastos. Con todo, el precio político (precio de coste) es la norma. El caso de las agencias privadas es radicalmente diferente y esperar la gratuidad en este sector es ilusorio.
- Licencias simples y acceso amplio: si la gratuidad total no es posible, los usuarios quieren como mínimo sistemas sencillos de registro y accesos colectivos (por ejemplo, todo el campus en el caso de las universidades). Los problemas técnicos en este aspecto son los mismos que con cualquier otra base de datos. Sólo los ficheros de microdatos comportan problemas especiales a causa de la confidencialidad de los datos.
- Formato electrónico: los usuarios siempre quieren este formato. Los motivos son evidentes: es una información que muchas veces se debe copiar, y hacerlo con el soporte en papel es largo, pesado y sobretodo abierto a muchos errores. Además, buena parte de los usuarios trabajará con estos datos utilizando un software estadístico. Por lo tanto, es necesario poder copiarlos con un formato electrónico que, además, sea compatible con el programa utilizado. Las agencias se han adaptado rápidamente y ofrecen no solamente la posibilidad de copiar o de bajarse los datos, sino también de hacerlo en los formatos informáticos más comunes.
- Interfaces: los usuarios quieren que la base de datos sea amigable. Y cuanto más inexperto sea el usuario, más importante es este punto. En esto las agencias están invirtiendo muchos esfuerzos debido a que Internet las ha abierto al gran público.
- Servicios de valor añadido: muchos usuarios indican que estarían dispuestos a pagar por búsquedas a medida... realizadas por la misma agencia. Estos usuarios no tienen ni tiempo ni ganas de aprender el funcionamiento de estas bases de datos. El problema es que las agencias son entidades de la Administración que no suelen ofrecer estos servicios. En la misma línea, se constata que la formación de usuarios sólo será valorada por quien deba utilizar las bases de datos de forma intensiva y a largo plazo.
En general, es más factible que se atienda el segundo tipo de demandas. Cambiar el método de acceso es mucho más fácil que tener que cambiar la metodología de los datos. Un ejemplo: una de las encuestas sociales más utilizadas por los investigadores es el Panel de Hogares de la Unión Europea. Esta gran encuesta tuvo ocho ediciones (denominadas waves, o sea, ‘olas’) entre 1994 y 2001. Pero se dejó de realizar porque se consideró que el coste que tenía no compensaba el beneficio en cuanto a diseño de políticas públicas. Los investigadores protestaron, ya que era una herramienta utilizada en multitud de proyectos en curso, pero Eurostat no ha cambiado de opinión.22
6 ¿Cómo buscar?
6.1 ¿Dónde buscar?
Al contrario de lo que se podría pensar, la búsqueda en sí de los datos no tiene mucha complicación. Lo que es complejo es saber dónde es necesario buscar. Los datos estadísticos son publicados y difundidos por las mismas agencias que los crean. Dicho de otro modo, es el usuario quien debe saber que la mejor fuente para datos españoles es el INE, pero que en el ámbito europeo debe buscar en Eurostat. O que para los datos financieros internacionales, la mejor fuente es el FMI, y para los de agricultura, el FAOStat. Por este motivo muchas “bibliografías” de datos estadísticos son en realidad listados de fuentes para cada temática concreta.
Existe una tendencia general a la unificación de estadísticas oficiales procedentes de distintas fuentes. Por ejemplo, el INE incluye en su base de datos más de treinta entidades de la administración central. Otra opción es ofrecer como mínimo una interfaz de búsqueda conjunta. Es la oferta de FedStats (http://www.fedstats.gov/) en Estados Unidos, que da acceso a más de setenta agencias gubernamentales. A pesar de ello, estos esfuerzos sólo se acostumbran a realizar en el ámbito de un solo país o de una misma administración. Para encontrar juntos los datos de diversas fuentes que no tienen ninguna relación orgánica entre ellas, es necesario recurrir a las bases de datos privadas.
6.2 Interfaces: problemas de diseño
“Public access information systems imply that most users will be first time users of the interface, and that they will have limited time and interest in learning the system”23 El diseño de interfaces para webs y bases de datos estadísticos es un tema de actualidad en la investigación documental. Al respecto las agencias estadísticas oficiales han realizado un gran esfuerzo. Las primeras webs de estas agencias solían consistir, simplemente, en las bases de datos ya existentes con el añadido de un motor de búsqueda más o menos preciso. Pero poco a poco la mayoría han pasado a un sistema de menú temático, más adecuado para usuarios no especialistas. Un ejemplo: Eurostat pasó de una oferta basada en cuatro bases de datos con nombres poco identificativos (New Cronos, Europroms, Comext, Regio) a otra basada en diez áreas temáticas.
También ha mejorado la usabilidad de las páginas. Hace unos años no era raro ver sitios web donde la base de datos en sí era difícil de encontrar entre las publicaciones, las noticias y la información institucional. Actualmente la situación es mucho mejor, y en la mayoría de los casos la información estadística es fácil de localizar. Otra cuestión es si el usuario encuentra los datos de libre acceso o de pago.
Marchionini (2002)24 hizo un interesante estudio longitudinal (cinco años) del web del Bureau of Labor Statistics (BLS) de Estados Unidos. Aparte de analizar los cambios de la interfaz, también incluyó entrevistas y encuestas a los trabajadores del BLS. Una de las conclusiones es que la explosión de Internet ha cambiado los métodos de trabajo de los funcionarios del BLS y los ha hecho más receptivos a las necesidades de los usuarios no especializados.
Para acabar, es necesario mencionar que ya han aparecido programas informáticos especializados en la publicación y el acceso a datos numéricos en Internet. Entre ellos, Nesstar (http://www.nesstar.com/) de UK Data Archive y el Norwegian Social Science Data Services, Beyond20/20 (http://www.beyond2020.com/), que utilizan muchas agencias internacionales (ONU, OCDE, etc.), o PCAxis (http://www.ine.es/prodyser/pcaxis/pcaxis.htm), que utiliza el INE.
6.3 Métodos de búsqueda
Una base de datos estadística suele combinar diferentes métodos de búsqueda, que pueden ser complementarios o alternativos. Pero no son los mismos que en el caso de la información textual.
Menús temáticos
Lo más habitual son los menús por temas. Se trata de una verdadera clasificación temática, en la que el usuario va abriendo carpetas hasta llegar a la serie que desee.
Figura 3. Menú temático de INEBase (http://www.ine.es/inebase/index.html).
Figura 4. Menú temático de Eurostat, sección “Economy and finance”
( http://epp.eurostat.cec.eu.int/portal/page?_pageid=0,1136173,0_45570701&_dad=portal&_schema=PORTAL)
La ventaja es que se trata de un sistema muy sencillo de utilizar, que permite una buena clasificación de la información. En general es ideal para los usuarios sin experiencia. El inconveniente es que, como todas las clasificaciones, es bastante rígido y puede ser confuso en lo que respecta a temas sin una ubicación clara. El usuario sin experiencia suele pasar mucho tiempo abriendo y cerrando secciones de la clasificación hasta que encuentra la información deseada. En los casos en los que una interfaz agrupe datos procedentes de diversas fuentes, además del menú temático, no es inusual ofrecer otro organizado según las agencias participantes.
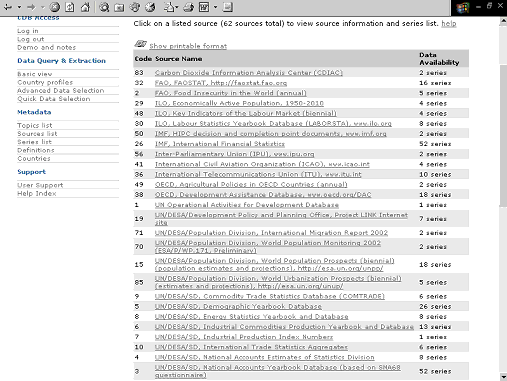
Figura 5. Menú de fuentes estadísticas de United Nations Common Database
Selección múltiple
La selección múltiple utiliza las cuatro variables más usuales de los datos estadísticos: el tema, el tiempo, el lugar y la unidad. Se trata de que el usuario elija cada una de las variables, y el sistema da como resultado una tabla estadística. En todos los casos se trata de un proceso lineal: tema + tiempo + lugar + unidad = resultado (con variaciones en el orden de los factores).
Esta selección se puede presentar de diversas formas:
a) Las cuatro opciones dentro de la misma pantalla, en cuadros de diálogo diferentes (INE).
b) Las cuatro opciones dentro de la misma pantalla pero en pestañas diferentes del sistema de búsqueda (Eurostat).
c) Las cuatro opciones en pantallas sucesivas (United Nations Common Database).

Figura 6. Ejemplo de selección múltiple en INEBase (http://www.ine.es/inebase/index.html).
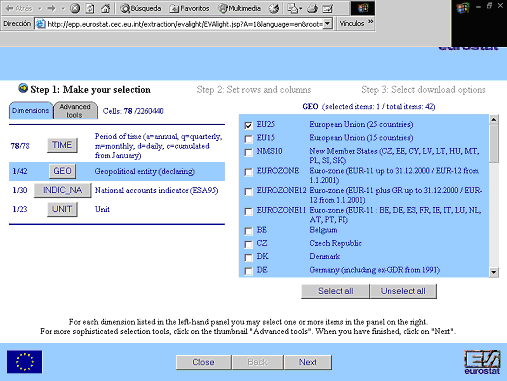
Figura 7. Ejemplo de selección múltiple en Eurostat, sección “Economy and finance”
( http://epp.eurostat.cec.eu.int/portal/page?_pageid=0,1136173,0_45570701&_dad=portal&_schema=PORTAL).
La selección múltiple es el método de búsqueda más “típicamente” estadístico, i es usual que se combine con un sistema de menú temático. Por ejemplo, la base de datos INEBase (http://www.ine.es/inebase/index.html) del INE tiene un sistema de menús, pero al final el usuario suele encontrar una selección variable/tiempo/lugar/unidad. En otros casos la base de datos ofrece de entrada la selección múltiple, pero la variable tema está organizada en forma de menú. Véase, por ejemplo, los indicadores del desarrollo mundial del Banco Mundial.
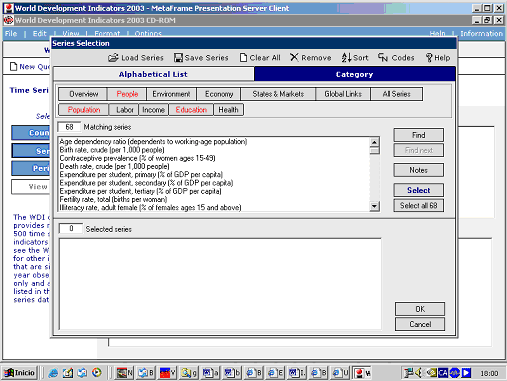
Figura 8. Ejemplo de selección de serie en World development indicators (Banco Mundial).
Este sistema tiene, básicamente, todas las ventajas. Los inconvenientes se pueden dar en usuarios sin experiencia que aún no dominen la terminología estadística.
Búsquedas por palabra clave o índice de materias
Este tipo de búsqueda, la típica de la información textual, es secundaria en el caso de las estadísticas. La razón es simple, el único “texto” donde se puede buscar son las descripciones de las series. Normalmente se ofrece como ayuda suplementaria para aquellos casos en que el usuario no encuentra lo que busca mediante los métodos anteriores. Es muy útil cuando el usuario no está seguro, o bien de la terminología que está utilizando, o bien de si lo que está buscando se encuentra en la base de datos.
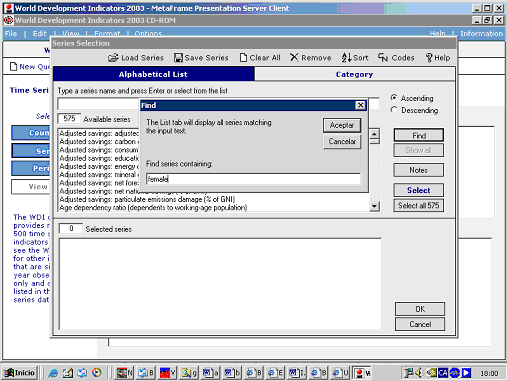
Figura 9. Búsqueda por palabra clave en World Development Indicators (Banco Mundial).
Una variante de la búsqueda por palabra clave es el índice de materias. Es decir, ofrecer alfabéticamente todos los temas presentes en la base de datos. Esto permite un nivel de detalle mucho más grande que un menú jerárquico.
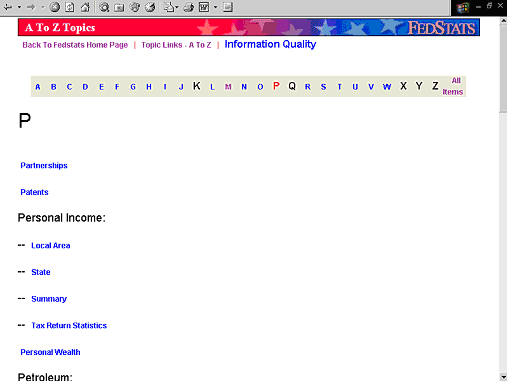
Figura 10. Índice de materias de FedStats (http://www.fedstats.gov/cgi-bin/A2Z.cgi)
La ventaja principal es que ofrece un método suplementario de localización de la información, y el inconveniente principal es que como método principal es muy limitado.
Búsquedas por código
Las búsquedas por códigos son posibles porque muchas bases de datos asignan un código (alfa) numérico a las series estadísticas. Normalmente el código tiene un significado intrínseco, de forma similar al código de la CDU. Si el usuario está familiarizado con estos códigos, puede hacer una búsqueda mucho más directa y precisa. Evidentemente este sistema sólo suele funcionar con usuarios avanzados, que trabajan de manera intensiva con la base de datos y, por lo tanto, han llegado a aprender el sistema de codificación. Para los usuarios sin experiencia u ocasionales, no tiene mucho interés.
En algunos casos los códigos los asigna la misma base de datos (es el caso de Datastream), pero en otros casos son códigos procedentes de clasificaciones nacionales o internacionales como, por ejemplo, la CNAE. Las más usuales son las clasificaciones de productos, que se utilizan en datos de producción o comercio.
Por ejemplo, en la base de datos International statistical yearbook (ISY) (base de datos privada, diversas fuentes, sección OCDE), el código 685211K significa:
68: Suiza
5211: Índice de precios al consumo. Comida (excluyendo los restaurantes)
K: Índice
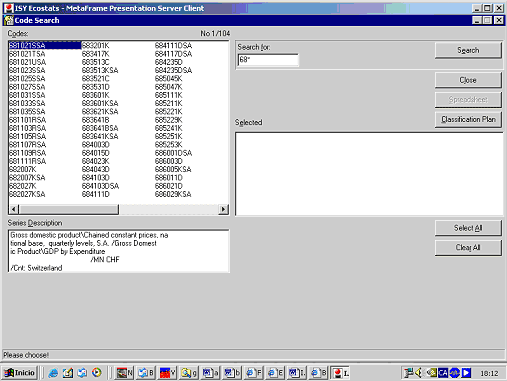
Figura 11. Búsqueda por código en International Statistical Yearbook (ISY)
Formato de los datos
Otra cuestión es el formato de salida de la información. La mayoría de las bases de datos ofrecen, por un lado, un formato de visualización en pantalla (HTML o Excel) para que el usuario pueda comprobar si son los datos que buscaba. En muchos casos el usuario también puede elegir los ejes de la tabla; dicho de otra manera, qué información quiere poner en las líneas horizontales y en las verticales. A continuación, o alternativamente, la base de datos ofrece diferentes formatos de salida. Los más habituales son las extensiones .csv (SPSS) y .xls (Microsoft Excel), que tienen la virtud, además, de ser compatibles con cualquier programa similar.
Microdatos: ficheros sin software de recuperación
Los microdatos, estrictamente hablando, no son bases de datos sino ficheros de datos. Esto quiere decir que, a pesar de incluir en algunos casos cantidades ingentes de información, no llevan incorporado un sistema de recuperación. Los usuarios copian estos ficheros y los abren con software estadístico especializado (SPSS, Stata o, incluso, Microsoft Excel).
En el caso de que una agencia sólo tenga un número limitado de ficheros, una simple lista en suficiente (ejemplo del INE, http://www.ine.es/prodyser/microdatos.htm).25 Si, en cambio, tenemos lo que se llama un archivo de datos sociales, lo más habitual es crear un registro de cada fichero (con las características principales) y aplicar un sistema de recuperación normal y corriente. Vea el Inter-university Consortium for Political and Social Research (ICPSR, http://www.icpsr.umich.edu/access/index.html) o el CIS.
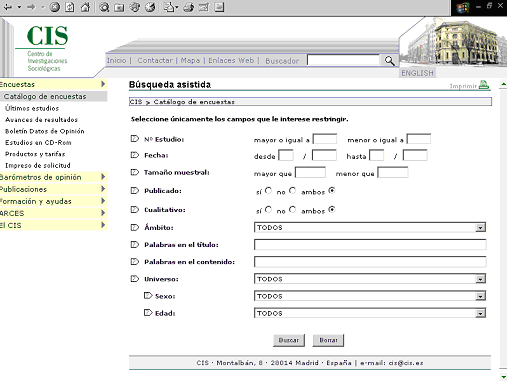
Figura 12. Formulario de búsqueda de encuestas del Centro de Investigaciones Sociológicas, CIS (http://www.cis.es/Page.aspx?OriginId=380).
6.4 Metadatos estadísticos
Con los metadatos estadísticos pasa lo mismo que con los dedicados a la información textual: estrictamente hablando no son nada muy nuevo. Siempre ha habido sistemas para describir y contextualizar los datos, normalmente desarrollados por las mismas agencias. Pero ahora Internet ofrece un incentivo para desarrollar estándares internacionales: la búsqueda y la recuperación conjuntas.
Así pues se han empezado a crear sistemas de metadatos estadísticos que aspiran a codificar todas las variables de los datos y, por tanto, a crear sistemas de búsqueda precisos y compatibles entre sí. Muchos de los proyectos se concentran en el ámbito de los ficheros de microdatos. La razón es simple: los microdatos son, simplemente, ficheros de datos y lo que los define es la documentación adjunta, especialmente el cuestionario y los códigos. Además, los microdatos son muchas veces de acceso restringido, pero en cambio la documentación siempre es de acceso libre.
Las iniciativas de metadatos proponen codificar toda esta documentación con un estándar internacional que haría posible la búsqueda conjunto. De los proyectos existentes, uno de los más importantes es el Data Documentation Initiative (DDI, http://www.icpsr.com/DDI/). Está promovido por el Inter-university Consortium for Political and Social Research (ICPSR), que se considera el archivo de datos sociales y microdatos de encuestas más completo a nivel internacional. Se está empezando a utilizar en diversas instituciones.26 Otros proyectos interesantes son: MetaDater (http://www.metadater.org/), proyecto conjunto de diversos archivos de datos europeos para la descripción de encuestas socioeconómicas, y MetaNet (http://www.epros.ed.ac.uk/metanet/), una red de proyectos europeos basados en las agencias oficiales. En general, se trata de proyectos dirigidos por estadísticos y no tanto por documentalistas. El más orientado al mundo bibliotecario es el DDI, que es compatible con el Dublin Core.
7 Datos agregados en las bibliotecas
“[...] it is not enough for reference librarians to be able to identify the sources for successful data retrieval. In order to deliver accurate and complete data reference service, it is also essential that the reference librarian understand how the user intends to statistically manipulate the data retrieved”27 7.1 ¿Qué datos para qué bibliotecas?
Teniendo en cuenta este contexto, ¿cuál es el papel de la biblioteca? La respuesta es: depende de la biblioteca. O, precisando aún más, depende del nivel de complejidad de las demandas de los usuarios. Si estos usuarios sólo piden datos agregados simples de forma concreta (caso de la mayoría de las bibliotecas públicas) con algunas publicaciones en papel, con las bases de datos de acceso libre por Internet y alguna de pago hay más que suficiente. En cambio, si lo que tenemos son investigadores de alto nivel en sociología, economía o epidemiología, seguramente necesitarán buenas bases de datos y también ficheros de microdatos, y esto implica un papel muy diferente para la biblioteca.
En nuestro país tenemos en contra la falta de tradición. Existen algunos ejemplos de secciones especiales, como por ejemplo la Unitat d’Estadístiques de la Biblioteca de Ciències Socials de la Universitat Autònoma de Barcelona (http://www.uab.es/servlet/Satellite?cid=1096479084704&pagename=BibUAB%2FPage%2FTemplatePlanaBibUAB), pero no son frecuentes. En cambio, en países anglosajones y especialmente en Estados Unidos es habitual encontrar data centers o data libraries en muchas universidades. Algunos ejemplos son: Edinburgh University Data Library (http://datalib.ed.ac.uk/index.html), University of Toronto Data Library Service (http://www.chass.utoronto.ca/datalib/) y GeoSpatial and Statistical Data Center de la University of Virginia Library (http://fisher.lib.virginia.edu/). En algunos casos existe un acuerdo con las agencias estadísticas nacionales y estas data libraries sirven también como centro de diseminación de datos. Seria el equivalente, en cuanto a estadísticas, a los centros de documentación europea. Véase, por ejemplo, el State Data Center Program (http://www.census.gov/sdc/www/) del US Census Bureau. Por lo tanto, en nuestro país aún tenemos mucho camino por recorrer.
7.2 ¿Qué datos se deben comprar?
Las bibliotecas no tienen un presupuesto ilimitado, y es necesario establecer unas prioridades claras. Por lo que respecta a los datos estadísticos, esto implica comprobar que lo que se quiere comprar no se puede encontrar gratuitamente en Internet. Es necesario recalcar que esta comprobación no siempre es fácil. Por razones de servicio público, las agencias continúan publicando en papel datos que también difunden exactamente igual por la web. A veces la única solución es comparar diversas series una a una. Conocer la política de la agencia también ayuda, pero es necesario tener en cuenta que esta puede cambiar de forma repentina.28
Como consecuencia, es recomendable que la biblioteca tenga una política de desarrollo de la colección para datos estadísticos. Y, debido al cambio acelerado actual, no estaría de más actualizarla cada uno o dos años. Esto permite examinar los sitios web de las agencias y ver qué ofrecen en libre acceso, que bajo suscripción, etc. Así se evalúa la colección de la biblioteca y se pueden planificar las prioridades de compra.
Publicaciones en soporte papel y referencia básica
Si analizamos uno a uno los posibles soportes de la información estadística, observaremos que las monografías y publicaciones periódicas tradicionales han ido a la baja. ¿Por qué razón? Los usuarios desean poder copiar fácilmente los datos, cosa imposible con el soporte papel. Esto no significa que el papel haya perdido toda su vigencia. La experiencia demuestra que es un medio excelente para usuarios sin experiencia. La clave reside en el hecho de que “soporte en papel” en la actualidad no quiere decir simplemente la tabla estadística pura y dura, sino una publicación donde se analizan los datos, se ofrecen explicaciones detalladas y se incluyen gráficos y mapas muy visuales. Para usuarios con pocos conocimientos de metodología, este tipo de fuente es la mejor. En otras palabras, se ha pasado a un soporte en papel con valor añadido. Pero antes de comprar también es necesario comprobar que esta publicación en papel no sea accesible de forma gratuita en formato pdf.
En el caso de consultas muy básicas, a veces la mejor fuente no son las agencias estadísticas, sino los anuarios de referencia básica. Son publicaciones o sitios web que analizan un tema a fondo (con datos estadísticos adjuntos) o dan información resumida sobre los países (incluida la estadística). Son anuarios del tipo Estado del mundo o sus equivalentes en Internet, como por ejemplo el CIA World Factbook (http://www.cia.gov/cia/publications/factbook/), los Country studies (http://news.bbc.co.uk/1/hi/country_profiles/default.stm) de la BBC o el recurso NationMaster (http://www.nationmaster.com/). También son útiles los anuarios de medios de comunicación que analizan un año concreto. El que publica El País, por ejemplo, tiene un anexo estadístico muy bien hecho. Y, en algunos casos, un artículo de prensa de una sola página puede ser una buena fuente. Los periodistas muchas veces llevan a cabo una tarea divulgadora: buscan la información en las agencias oficiales y la transforman en una tabla, un gráfico o un mapa adecuados al público en general. En este sentido, es necesario decir que es lamentable que algunas bases de datos de prensa (como por ejemplo MyNews) no incluyan las ilustraciones y los gráficos de los artículos.
Para acabar, el soporte en papel es también importante para la alta investigación en un ámbito muy concreto: los datos más antiguos. A pesar que la situación mejora progresivamente, muchas agencias sólo ponen en Internet los datos que ya tenían informatizados en origen. Esto deja fuera la información estadística publicada en el siglo XIX y buena parte del XX. Se han publicado algunos CD-ROM con datos históricos, como por ejemplo el United Nations Demographic Yearbook. Historical Supplement (1948–1997). Pero en la mayoría de los casos se ha de recurrir al papel en forma de anuarios antiguos. Si no los tenemos en nuestra biblioteca, es necesario buscar una con buenos fondos históricos y utilizar el préstamo interbibliotecario. Existen dos tipos de bibliotecas especialmente interesantes: a) las bibliotecas especializadas en economía y b) las bibliotecas de las mismas agencias estadísticas, que suelen ser el depósito de las publicaciones de estas.29
Soportes electrónicos de acceso local
Los disquetes y los CD-ROM fueron el método de difusión preferido por las agencias antes de Internet. Se comercializaban por sí mismos o como material de acompañamiento de anuarios y revistas. Con Internet, esto ha cambiado y han sido sustituidos en gran parte por bases de datos de libre acceso o de suscripción. Puede ser que en algunos casos la biblioteca continúe interesada en un soporte local. Ya sea porque aún es la única manera de adquirirlo, o porque es más barato (las versiones remotas de pago suelen ser más caras), o porque nos llega acompañando una publicación en papel. Pero lo más importante es ofrecer la máxima disponibilidad: instalar los CD-ROM en una red local o ponerlos disponibles para préstamo. De esta forma, el usuario puede trabajar desde donde quiera. Una base de datos de acceso totalmente local dentro de la biblioteca sólo será consultada si es realmente imprescindible. En caso contrario, es una compra inútil.
Internet: fuentes de pago
Para las bases de datos de acceso remoto pero de pago, sólo es necesario seguir los mismos criterios que para las demás bases de datos de la biblioteca: accesos que sean tan amplios como sea posible (red, campus, etc.) y buena selección cuando hay diversas opciones.30 En bases de datos similares, es necesario poner especial atención en la cobertura cronológica (lo más amplia posible), la facilidad de uso de la interfaz y el formato de salida de los datos (compatible con los principales programas de software estadístico).
Internet: fuentes de acceso libre
Las fuentes de libre acceso por Internet no habrían de comportar más problemas que una buena descripción dentro de la web, el catálogo o la guía temática de la biblioteca. Se trata, simplemente, de facilitar el acceso a los usuarios que no conocen las fuentes y, por lo tanto, necesitan un poco de orientación. Cada vez hay más datos gratuitos, una tendencia que facilita el acceso de los usuarios y permite a la biblioteca liberar presupuestos para otras bases de datos. Nuestra tarea es complementar y facilitar el acceso a Internet, no hacerle la competencia.
7.3 ¿Cómo difundir la información y atender a los usuarios?
Tan importante como la selección y la adquisición de estos datos es la difusión que se haga de los mismos. Muchas veces en las bibliotecas se hace poco marketing, y en cambio se trata de algo fundamental. Si se compra una base de datos pero no se realiza la difusión de la misma, es como si no existiera. Si se tiene un buen conocimiento de las fuentes pero no se informa a los usuarios, estos no preguntarán. Si una base de datos que antes era de pago pasa a ser de acceso libre, esto es una buena noticia que se ha de difundir. En resumen, la biblioteca ha de dar la sensación que domina todo tipo de fuentes estadísticas, sea cual sea el método para acceder a la misma.
El primer nivel de difusión es tan simple como una buena colocación en el sitio web y una descripción precisa en el catálogo de la biblioteca. Debido a que las estadísticas son un tipo de información y no un tema, existen dos formas de incorporarlas a los sitios web: en un apartado específico (generalmente con otros recursos electrónicos como revistas o bases de datos) o insertadas dentro de distintas páginas temáticas. Cada centro decidirá qué le va mejor. Lo que es importante es combinar siempre las fuentes de pago con las gratuitas.
Un segundo nivel de difusión es la formación de usuarios. Sin embargo, es necesario tener cuidado, ya que no todos los usuarios desean ser formados. Si una persona necesita un dato concreto, lo más adecuado es dirigirla a la fuente adecuada y no ir más allá. La formación, en cambio, puede interesar a los usuarios que prevén un uso intensivo y a largo plazo de estas fuentes. En el ámbito universitario o especializado, puede ser una buena idea realizar presentaciones al profesorado. Ya sea de forma concreta en el caso de nuevos servicios, ya sea una introducción general a las fuentes disponibles para los usuarios que acaban de llegar a la institución. Los destinatarios de preferencia serán investigadores, profesores y doctorandos. Pero si se dispone del permiso y la colaboración del profesorado, se pueden también realizar sesiones introductorias para el alumnado de primer y segundo ciclo.
En el caso de las universidades, el proceso de convergencia en Bolonia y la renovación pedagógica que implica abre perspectivas muy interesantes. Por ejemplo, la posibilidad de crear “laboratorios estadísticos” dentro de la biblioteca, similares a los “laboratorios de lenguas”. En estos laboratorios habría documentación metodológica, programas estadísticos y la posibilidad de organizar cursos. Por ejemplo, impartir clases sobre software estadístico.
Para acabar, si es necesario, se tiene que ir a buscar a los usuarios. En algunos casos es difícil, pero en centros de investigación o universidades es factible porque las categorías de usuarios están bien delimitadas (por ejemplo, el profesorado de economía). Es necesario realizar mucho trabajo de relaciones públicas, ofrecer los servicios de la biblioteca y proporcionar servicios de valor añadido. A modo de ejemplo, se pueden crear boletines de novedades por correo electrónico, aunque nueve de cada diez boletines de este tipo acabarán directamente en la papelera sin ser leídos. Esto es normal y no habría de desanimar a los bibliotecarios. Lo que es importante es que los usuarios entren en contacto con el servicio.31
8 Microdatos en las bibliotecas
“People who will happily allow unknown corporations to track their Internet reading, electronic shopping behavior and spending patterns are worried that egg-heads like myself will try to find out where they live”32
8.1 Datos base en las bibliotecas
La problemática que rodea los microdatos se ha dejado para el final debido a su complejidad. Recordemos que los microdatos son ficheros donde se recogen los resultados individualizados de las encuestas sociales o de opinión. Es un tipo de datos base que por regla general sólo se necesita para la investigación, especialmente en las ciencias sociales, o bien para la docencia, cuando se trata de formar futuros investigadores.
Es un tipo de fichero que muchas veces no se encuentra en nuestras bibliotecas simplemente porque no hay mucha tradición al respecto. En Estados Unidos es más habitual, debido a los data centers que muchas agencias productoras instalaron dentro de las bibliotecas universitarias. Pero en España es tan inusual, que cuando la Biblioteca de la Universitat Pompeu Fabra intentó por primera vez adquirir microdatos del INE (primavera de 2003), éste se mostró reticente a causa, precisamente, de que se trataba de una biblioteca (porque la asimilaba a servicios de acceso libre y sin restricciones).33
En nuestro país es más usual que los investigadores adquieran los datos individualmente o por grupos de investigación, a cuenta de ayudas y presupuestos del departamento universitario al que pertenecen. Esto es práctico para ellos, pero implica un escaso control de los ficheros, peligro de duplicación y, habitualmente, falta de planificación. ¿Podrían las bibliotecas, especialmente las universitarias o de investigación, hacerse cargo de este material? La respuesta es que sí. El problema es que los microdatos están sujetos al denominado secreto estadístico.
8.2 El problema del secreto estadístico
¿Qué es el secreto estadístico? Según el INE, es “la prohibición de difundir estadísticas o datos en que no se conserva el anonimato de cada unidad individual a la cual se refiere la información”. El secreto estadístico, por lo tanto, no tiene nada que ver con los derechos de autor, sino con la privacidad. Para entender el problema imaginemos una encuesta sobre opiniones políticas. Si alguien llega a saber quien es el entrevistado número X, sabrá muchísimo sobre cuestiones muy personales y delicadas. Por este motivo, el secreto estadístico no solamente es un problema de ética profesional de estadísticos e investigadores, sino también un problema legal. Las leyes de protección de datos personales imponen restricciones y castigos severos a los infractores, como mínimo en teoría.
A fin de proteger la privacidad de los datos, existen dos métodos: en origen o en destino. En origen se trataría de difundir los datos sin los elementos más identificadores. Por ejemplo, todos los microdatos que se utilizan para investigación están anonimizados: se han eliminado de los mismos todos los nombres, direcciones, etc. Pero esto no es suficiente en casos de unidades geográficas pequeñas o categorías con pocas respuestas. Imaginemos que el entrevistado es una mujer, casada y con dos hijos, con estudios superiores, que trabaja de administrativa y nacida en 1960: esta descripción en una zona con pocos habitantes es más que suficiente para identificar a una persona. Por este motivo, muchas agencias optan por agrupar unidades o borrar variables. Pero son técnicas que no gustan a los investigadores, que temen que sus resultados se resientan.
Si los datos no se han podido proteger suficientemente en origen, se limita el acceso a los usuarios finales. Las limitaciones se especifican en las licencias de uso. Las condiciones usuales son el uso individual de los datos y la prohibición de difundirlos a cualquier persona que no haya firmado la licencia. También es habitual que se pidan cada año listados de usuarios y listados de publicaciones realizadas en base a los datos. De manera menos frecuente, se puede prohibir o limitar severamente la copia de los datos, incluso para uso personal. Se pueden encontrar incluso casos en que los microdatos son gratuitos (para investigación), pero en que sigue siendo necesario firmar una licencia de uso.
Les agencias toman estas precauciones porque temen perder la confianza del público. Si las encuestas han de ser fiables, la gente ha de contestarlas sinceramente, y no lo hará si cree (o sospecha, aunque sea sin fundamento) que sus respuestas no son confidenciales. Los investigadores pueden estar de acuerdo en teoría, pero discrepan en cuanto a la gravedad de las medidas. Argumentan que actualmente, cando multitud de datos personales circulan por la red y están en manos de empresas privadas, preocuparse excesivamente por los datos que están en manos de economistas o sociólogos es exagerado.34
8.3 Gratuidad, pago y archivos de datos sociales
Un poco al margen de este debate, las bibliotecas dependerán mucho del método de seguridad que se haya utilizado. Si se ha puesto énfasis en la restricción en origen, podemos encontrar microdatos que son simplemente de libre acceso, igual que los datos estadísticos. Si la restricción es en destino, las bibliotecas se han de comprometer a restringir el acceso, por ejemplo mediante redes restringidas a usuarios individuales. También deben comprometerse a realizar las gestiones que pida la agencia (mantenimiento de listados de usuarios, recogida de bibliografía producida, etc.). Es importante que la biblioteca pueda difundir que dispone de este material, siempre que se dejen muy claras las restricciones de acceso.35
Al igual que los datos estadísticos agregados, el acceso a los microdatos está en continua evolución. Es difícil saber cómo será el acceso dentro de unos años. Pero existen diversas posibilidades que no se excluyen entre sí:
- Acceso libre: es perfectamente posible cuando los datos están muy anonimizados. En Estados Unidos ya hace décadas que una parte del censo se ofrece libremente para la investigación, docencia y aprendizaje (el PUMS: Public Use Microdata Samples, http://www.census.gov/main/www/pums.html). Diferentes agencias nacionales ya se acogen a esta posibilidad. En nuestro país, el INE (http://www.ine.es/prodyser/microdatos.htm) se ha decidido por el acceso libre desde junio de 2005.36 En algunas agencias se requiere un simple registro en línea del usuario, que sin comprobación de los datos es prácticamente igual que el libre acceso. En este caso la biblioteca no intervendrá excepto para aconsejar a los usuarios.
- Acceso restringido: el acceso se restringe a determinadas categorías de usuarios:
- Institucional en línea: para universidades, centros de investigación, etc. El papel de la biblioteca sería similar al de cualquier otra base de datos. Una variante cada vez más usual es hacerse socio de consorcios de datos sociales (membership). Es el ejemplo de ICPSR (http://www.icpsr.com/).
- Institucional en soporte físico: los datos se entregan en CD-ROM o se envían por correo electrónico. Es la institución quien ha de gestionar y limitar el acceso. En los dos casos, la institución es legalmente responsable de la protección de los datos personales.
- Individual en línea o en soporte físico: la agencia proporciona directamente los datos al usuario si este ha justificado el interés por los mismos. El usuario es individualmente responsable.
9 La investigación documental
“There is a rich literature on information seeking, both in general and for specific contexts. However, little empirical evidence is available concerning how people seek and use statistics”37 Un estado de la cuestión sobre la investigación documental en datos estadísticos merecería un artículo aparte. Por lo tanto, sólo expondremos las características, los métodos y las temáticas más relevantes.38
La primera constatación es que los trabajos de investigación en este tema no son muy abundantes, especialmente si lo comparamos con la investigación dedicada a las bases de datos bibliográficas o la información textual. Una búsqueda en LISA o Library Literature and Information Abstracts demuestra que las estadísticas están mucho más estudiadas como método que como objeto específico de estudio.
La segunda es que delimitar la investigación estrictamente documental no es fácil. Bibliotecarios y documentalistas llevan a cabo investigación muy general que publican en revistas de fuera de su ámbito profesional, mientras que en revistas de documentación aparecen trabajos firmados por profesionales de otros campos (matemáticos, estadísticos, sociólogos, informáticos, etc.). Esta última categoría de autores puede llegar a representar hasta una tercera parte de la investigación total. Por profesiones, son mayoría el profesorado de universidad y el alumnado de doctorado (no necesariamente en documentación), seguidos de bibliotecarios de universidad y de centros especializados. Por nacionalidades, son aplastante mayoría los autores procedentes de países anglosajones (en especial de Estados Unidos y el Reino Unido), donde se pueden detectar diversos núcleos y grandes proyectos de investigación. Los más destacados serían:
- GovStat Project (http://www.ils.unc.edu/govstat/): proyecto conjunto de la University of North Carolina Interaction Design Lab y la University of Maryland Human-Computer Interaction Lab, desarrollado entre julio de de 2002 y junio de 2005. Está dirigido por algunos de los mejores investigadores en el tema (o como mínimo los más prolíficos): Gary Marchionini, Carol Hert, Stephanie W. Haas, Ben Shneiderman y Catherine Plaisant. Este proyecto tiene como objetivo la “integración de datos e interfaces para mejorar la comprensión humana de estadísticas gubernamentales”, resumido en su lema “find what you need, understand what you find”. Se debe decir que cuenta con el apoyo de la Administración de Estados Unidos, y que ha llevado a cabo numerosos estudios y evaluaciones de los web estadísticos oficiales de dicho país.
- Statistical Knowledge Network: todavía en contrucción, quiere ser la continuación del proyecto GovStat, pero con un énfasis especial en diseño de interfaces y sistemas de metadatos.
- Project on the Use of Numeric Data in Learning and Teaching, 2001–02 (http://datalib.ed.ac.uk/projects/datateach.html): proyecto conjunto de Edinburgh University Data Library, EDINA, UK Data Archive, MIMAS y British Library of Political and Economic Science. Evaluó el uso de los datos estadísticos en la docencia universitaria del Reino Unido.
- Data Documentation Initiative (DDI, http://www.icpsr.umich.edu/DDI/): proyecto de metadatos del Inter-university Consortium for Political and Social Research (ICPSR, http://www.icpsr.umich.edu/). Es el proyecto de metadatos estadísticos más destacado.
- MetaDater (http://www.metadater.org/): proyecto conjunto de diversos archivos de datos europeos para la descripción de encuestas sociológicas.
- MetaNet (http://www.epros.ed.ac.uk/metanet/): proyecto similar, llevado a cabo entre el 2000 y el 2003, que quería coordinar diversos proyectos de metadatos generados por diversas agencias estadísticas oficiales europeas.
En lo que respecta a los temas más usuales, se podrían dividir en tres grandes ejes:
- Interfaces: estudios de usabilidad, nuevos prototipos y software de búsqueda, etc., incluidas las propuestas de metadatos.
- Usuarios: tipologías, métodos de búsqueda, expectativas y quejas, necesidades, etc., así como los problemas legales de los microdatos y la cuestión de la alfabetización estadística.
- Recopilaciones de fuentes: lo que en otros ámbitos sería bibliografía.
Muchas veces se encuentras investigaciones que combinan distintos temas.
En general, muchos trabajos repiten la misma idea: se trata de un ámbito muy nuevo, que en poco tiempo ha puesto al alcance del público una enorme cantidad de información, pero con unos métodos de búsqueda pensados para especialistas y pocos conocimientos sobre métodos de búsqueda y necesidades de los usuarios. De aquí que el aumento de trabajos de investigación siga de cerca la explosión de Internet; y que haya un interés especial en métodos de búsqueda y recuperación dirigidos a usuarios no especialistas. Algunos ejemplos: sistemas de metadatos que faciliten la búsqueda, estándares de descripción compatibles entre sí, formatos de visualización (presentación de los datos) adaptados a personas con pocos conocimientos de estadística, sistemas de ayuda dinámica, creación de gráficos y mapas simples y amigables, sistemas capaces de recordar las búsquedas más usuales y de aprender del usuario, etc.
Sin embargo, de momento muchos de estos trabajas aún son investigación descriptiva, con un predominio claro de encuestas y trabajos de usabilidad. Pero con la publicación creciente de trabajos y la consolidación de proyectos de investigación se prevé un buen futuro para esta rama de la investigación documental.
10 Conclusiones
A lo largo de este artículo se han ido exponiendo diversas conclusiones. Quizás la que podría finalizarlo es muy simple: todo este ámbito está en un momento de profundo cambio. Lo que hoy es posible no lo era hace cinco años, y seguramente dentro de cinco años más los cambios serán aún mayores. Las bibliotecas pueden sentirse un poco desconcertadas, ya que muchos datos que antes gestionaban ahora son de acceso libre. Es importante encarar estos cambios como una oportunidad y no como una amenaza. Y no hemos de perder de vista nuestra función principal: facilitar el acceso a la información. Muchas fuentes son de libre acceso, pero no son fáciles de encontrar ni de consultar. Por lo tanto, es importante que los usuarios encuentren en las bibliotecas todas las facilidades posibles y personal experto. Y no se debe olvidar que algunas bases de datos estadísticas son tan caras que muchos usuarios sólo podrán consultarlas si las bibliotecas las compran. Tenemos un papel por desarrollar, y es importante que los usuarios perciban que la información estadística forma parte de la oferta de la biblioteca.
11 Bibliografía
Bennet, Terrence B.; Nicholson, Shawn W. (2004). “Interactions between the academic business library and research data services”. Portal: libraries and the academy, vol. 4, no. 1, p. 105–122.
Blakemore, Michael; McKeever, Lucy (2001). “Users of official European Statistical data. Investigating information needs”. Journal of librarianship and information science, vol. 33, no. 2, p. 59–68.
Denn, Sheila; Haas, Stephanie W. (2003). “Statistical metadata during integration tasks”. En: DC-2003 (September 28 – October 2, 2003, Seattle, WA). http://www.siderean.com/dc2003/301_Paper50.pdf. [Consulta: 13/09/2005].
Estrugas Mora, Gemma; Riera Masgrau, Roser (2000). “Panoràmica de la producció catalana de fonts estadístiques en suport electrònic”. Item, núm. 26, p. 36–88.
Hert, Carol A.; Marchionini, Gary (1998). “Information seeking behavior on statistical websites. Theoretical and design implications”. En: Proceedings of the American Society for Information Science Annual Meeting (ASIS'98). Pittsburg: American Society for Information Science, p. 303–314.
Hyland, Peter; Gould, Ted (1998). “External statistical data: understanding users and improving access”. International journal of human-computer interaction, vol. 10, no. 1, p. 71–83.
Marchionini, Gary (2002). “Co-evolution of user and organizational interfaces: a longitudinal case study of WWW dissemination of national statistics”. Journal of the American Society for Information Science and Technology, vol. 53, no. 14, p. 1192–1209.
Marxhall, Gordon (ed.) (1998). A dictionary of sociology. Oxford: Oxford University Press.
Montanyà, Rosa; Pozuelo, Coro (2005). “Fitxers de microdades a la Biblioteca de la UPF”. 1r Espai CBUC d’Intercanvi de Coneixements i Experiències.
Roba Stuart, Óscar (2003). “Archivos de datos en línea para ciencias sociales”. El profesional de la información, vol. 12, nº 5, p. 400–410.
Salkind, Neil J. (2004). Statistics for people who (think they) hate statistics. 2nd ed. Thousand Oaks: Sage.
Tupek, A.; Dippo, C. (1997). “Quantitative literacy : new website for federal statistics provides research opportunities”. D-Lib magazine (Dec. 1997). http://www.dlib.org/dlib/december97/stats/12tupek.html. [Consulta: 13/09/2005].
Direcciones de Internet de interés
- Data Documentation Initiative (DDI): http://www.icpsr.umich.edu/DDI/
- GovStat Project: http://www.ils.unc.edu/govstat/
- Instituto Nacional de 39Estadística (INE). Sistema Estadístico Nacional: http://www.ine.es/ine/sistestanac.htm
- Inter-university Consortium for Political and Social Research (ICPSR): http://www.icpsr.umich.edu/
- Project on the Use of Numeric Data in Learning and Teaching: http://datalib.ed.ac.uk/projects/datateach.html
- Statistical Literacy: http://www.statlit.org/
[Consulta: 13/09/2005]
Fecha de recepción: 15/09/2005. Fecha de aceptación: 05/10/2005.
Notes
1 Algunas perlas similares: “Torture the data long enough and they will confess to anything”, “Statistics: group of numbers looking for an argument”, “Statistics: fiction in its most uninteresting form” y “Statistician: a man who can go directly from an unwarranted assumption to a preconceived conclusion”.
2 Sheila Denn, Stephanie W. Haas, “Statistical metadata during integration tasks”. En: DC-2003 (September 28 – October 2, 2003, Seattle, WA), p. 7. http://www.siderean.com/dc2003/301_Paper50.pdf.
3 Para las definiciones se han utilizado diversas fuentes: ODLIS-Online Dictionary for Library and Information Science (http://www.wcsu.edu/library/odlis.html), Cercaterm del Termcat (http://www.termcat.net/) y Dictionary of Sociology, 2nd ed. (Oxford University Press, 1998).
4 En este trabajo se utilizará el término “fichero” como traducción de “file” aunque “archivo” sea más utilizado generalmente. El objetivo es diferenciar claramente “fichero (informático) de datos”, de “archivo de datos” (centro que recopila y gestiona este tipo de ficheros).
5 Diccionario de la Lengua Española. 22ª ed. Ed. en CD-ROM. Madrid: Real Academia Española : Espasa, 2003.
6 A. Tupek, C. Dippo, “Quantitative literacy”, D-Lib magazine (Dec. 1997), http://www.dlib.org/dlib/december97/stats/12tupek.html.
7 Carol A. Hert, Gary Marchionini, “Information seeking behavior on statistical websites: theoretical and design implications”. En: Proceedings of the American Society for Information Science Annual Meeting (ASIS'98). (Pittsburg: American Society for Information Science, 1998), p. 304.
8 En inglés podemos encontrar algunos sinónimos más o menos exactos: data center, ‘centro de datos’ o bien statistical institute, ‘instituto de estadística’ —este último, aplicado generalmente a los centros nacionales de cada país, com por ejemplo el INE.
9 Un nombre genérico para este tipo de agencia oficial central es instituto estadístico.
10 Un caso muy conocido son las empresas que llevan a cabo encuestas electorales: Demoscopia, Sofres, etc.
11 De hecho, las empresas que se limitaban a recopilar datos sin mejorar la recuperación de los mismos están desapareciendo, víctimas del libre acceso a las webs estadísticas oficiales.
12 Citado por Michael Blakemore, Lucy McKeever, “Users of official European statistical data: investigating information needs”. Journal of librarianship and information science, vol. 33, no. 2 (June 2001), p. 60.
13 Durante los primeros años de Internet la complejidad de las bases de datos estadísticas comportaba también problemas. Con conexiones lentas, hacer consultas completas y bajar una gran cantidad de datos podía acabar con la paciencia del usuario. Pero esto se ha solucionado de manera natural, a medida que las conexiones han mejorado.
14 Michael Blakemore, Lucy McKeever, “Users of official European statistical data: investigating information needs”. Journal of librarianship and information science, vol. 33, no. 2 (June 2001), p. 66
15 Mark Witter, “Nesstar: providing a data web by building web based data, sharing environments, portals, and observatories”, Burisa, no. 162 (Dec. 2004), p. 5.
16 Sobre esto, es recomendable leer la entrevista al matemático Mogens Niss en “La Contra” de La vanguardia del 20 de mayo de 2005 (http://wwwd.lavanguardia.es/Vanguardia/Publica?COMPID=51185100396&ID_PAGINA=781&ID_FORMATO=9). Un ejemplo: “un diputado danés que explicó que el 68 % de la población no usaba librerías porque el 37 % de los hombres y el 31 % de las mujeres no las visitaba nunca”.
17 Cita de Andrew Lang (1844–1912).
18 Se lleva a cabo un gran esfuerzo docente dirigido especialmente a los estudiantes universitarios. No existen muchos problemas con los estudiantes de matemáticas o de estadística. En cambio, muchos estudiantes de ciencias sociales (economía, sociología, etc.) tienen serias dificultades con los métodos cuantitativos.
19 Se puede encontrar una selección de este material en la página web “Estadística para las ciencias sociales” (http://www.upf.edu/bib/guies/guies.htm?opcio=/bib/ccpp/sociologia/metstat.htm) de la Biblioteca de la Universitat Pompeu Fabra.
20 Michael Blakemore, Lucy McKeever, “Users of official European statistical data: investigating information needs”. Journal of librarianship and information science, vol. 33, no. 2 (June 2001), p. 62.
21 Carol A. Hert, Gary Marchionini, “Information seeking behavior on statistical websites: theoretical and design implications”. En: Proceedings of the American Society for Information Science Annual Meeting (ASIS'98). (Pittsburg: American Society for Information Science, 1998), p. 306.
22 Eurostat al final (verano de 2005) lo ha cambiado por una encuesta similar, pero que no incluye las mismas preguntas, lo que disminuye mucho su valor para la investigación.
23 Hyunmo Kang, Catherine Plaisant, Ben Shneiderman, “New approaches to help users get started with visual interfaces: multi-layered interfaces and integrated initial guidance”. Proceedings of the Digital Government Research Conference, Boston, MA. (May 2003).
24 Gary Marchionini, “Co-evolution of user and organizational interfaces: a longitudinal case study of WWW dissemination of national statistics”. Journal of the American Society for Information Science and Technology, vol. 53, no. 14 (2002), p. 1192–1209.
25 Los ficheros de microdatos que puede crear una agencia son pocos en comparación con la cantidad de series estadísticas que se derivan de los mismos.
26 Vea ejemplos de instituciones que utilizan el Data Documentation Initiative (DDI) en la siguiente dirección: http://www.icpsr.umich.edu/DDI/codebook/projects.html.
27 Terrence B. Bennet, Shawn Nicholson, “Interactions between the academic business library and research data services”. Portal: libraries and the academy, vol. 4, no. 1 (2004), p. 107.
28 Por ejemplo, Eurostat decidió de repente poner en acceso libre todos sus datos agregados en octubre de 2004, y el INE dio acceso a sus microdatos en junio de 2005. Ambas decisiones comportaron un cambio radical de política.
29 Si es necesario ponerse en contacto con una agencia estadística, es mejor hacerlo directamente con su biblioteca o su centro de documentación: la solidaridad profesional funciona.
30 Algunas agencias internacionales ofrecen los datos básicos o la consulta simple grátis, pero los búsquedas voluminosas y/o la copia de los datos requieren una subscripción.
31 La experiencia de la Universitat Pompeu Fabra es positiva en este aspecto. No ha habido peticiones de baja del servicio, a pesar de que la opción es bien visible. Y la cantidad de mensajes con preguntas, dudas, etc recibidos como respuesta del boletín denotan que el servicio es útil.
32 Citado por Alice Robbin, “The loss of personal privacy and its consequences for social research”. Journal of government information, vol. 28 (2001), p. 509.
33 En junio de 2005, en cambio, el INE puso estos archivos en acceso completamente abierto.
34 De aquí proviene la cita que encabeza este apartado.
35 En contra de lo que se podría pensar, los usuarios entienden perfectamente las restricciones. Además, es necesario tener unos conocimientos de estadística bastante avanzados para poder aprovechar los datos, lo que limita el número de usuarios de forma natural.
36 Es necesario decir que el INE ha pasado de ser reaccio a vender los microdatos a bibliotecas a ofrecerlos a todo el mundo por medio de su web ¡Es un cambio de 180 grados en muy pocos años!
37 Carol A. Hert, Gary Marchionini, “Information seeking behavior on statistical websites: theoretical and design implications”. En: Proceedings of the American Society for Information Science Annual Meeting (ASIS'98). (Pittsburg: American Society for Information Science, 1998), p. 304.
38 Esta sección se basa en el trabajo “La investigació en bases de dades numèriques/estadístiques”, para la asignatura Mètodes i tècniques en investigació documental del programa de doctorado Informació i Documentació en l’Era Digital (Universitat de Barcelona, curso 2003–04).