Molts articles, informes i presentacions recents de l'àmbit de la biblioteconomia han identificat canvis ambientals, tecnològics i filosòfics notables que ens exigeixen repensar completament com les biblioteques duen a terme el control bibliogràfic.1
Fins i tot el terme control bibliogràfic és un anacronisme:
Bibliogràfic: aquest terme està molt relacionat amb la literatura publicada —principalment, llibres, però també, en certa manera, diaris—, però no ho està gaire amb les múltiples formes de comunicació que s'utilitzen avui en dia a Internet. Quan es recullen llocs web, quina part podríem anomenar bibliogràfica? Com de bibliogràfic és, per exemple, un blog col·laboratiu? Necessitem urgentment un terme més general i més genèric; a falta d'una idea millor, he decidit triar descriptiu, ja que, sigui quin sigui el recurs, bàsicament estem parlant de descriure un recurs.
Control: què cal que n'expliqui? Google digitalitza d'una manera massiva els continguts de les biblioteques més importants i posa a disposició el resultat per a la cerca de text complet. LibraryThing.com, entre d'altres, té força èxit en permetre que qualsevol persona assigni els termes que se li acudeixin als llibres que té. Si no fossin més que bestieses i s'ignoressin sense més, seria una cosa, però no és així i no podem…
Ja no crec en el futur del control bibliogràfic. Ja no crec que el terme bibliogràfic abraci l'univers en què hauríem d'estar interessats, i ja no crec que el control sigui possible ni tan sols desitjable. Hem entrat a l'era de l'enriquiment descriptiu i serà millor que se'ns doni prou bé.2
Per enriquiment descriptiu entenc un conjunt de procediments, humans, mecànics i combinats, mitjançant els quals captem la informació descriptiva d'un ítem o una col·lecció i la millorem d'una manera continuada i iterativa. Potser una distinció encara més important que caldria fer respecte de les pràctiques anteriors és que aquest procés de millora de les dades hauria d'incloure no sols els bibliotecaris professionals, sinó també els usuaris de les biblioteques.
En la Conferència Anual del 2008 de l'American Library Association, Joe Janes va explicar que en una ocasió havia sentit algú preguntar "què passaria si un llibre millorés cada cop que el llegíssim?", que ell va reformular com "què passaria si una biblioteca millorés cada vegada que s'utilitza?".3 Aquest procés de millora a través de l'ús és el que intentaré descriure. Per això, també evito el terme catalogar, que denota un procés professional efectuat per catalogadors formats. Voldria suggerir que en fer servir el terme més ampli metadada, podem abraçar no solament la catalogació bibliotecària, sinó també altres activitats que contribueixen a la informació descriptiva sobre els ítems i la milloren.
L'objectiu de la descripció bibliogràfica
Per saber si finalment els nostres esforços de reenginyeria de les nostres pràctiques bibliogràfiques són reeixits, hem d'establir quin és el nostre objectiu en fer aquestes activitats. Crec que el nostre objectiu hauria de ser permetre que persones independents i autosuficients trobin el que busquen. Especifico independents i autosuficients a propòsit, ja que crec que és el que gairebé tothom voldria ser. La majoria d'usuaris de biblioteques prefereixen no haver de parlar amb un bibliotecari. La majoria prefereixen trobar ells sols el que busquen, tot i que els costi i no se'ls doni bé. Llavors, la nostra feina és fer que el procés de cerca sigui tan senzill com sigui possible.
Això significa que les estratègies bibliogràfiques més eficaces seran les que no siguin evidents per a l'usuari; és a dir, són tan intuïtives que queden en un segon pla i les coses simplement funcionen. Per aconseguir-ho cal ocultar a l'usuari bona part de la complexitat. És a dir, per ser simples de cara enfora, els nostres sistemes han de ser complexos de cara endins. Fins a aquest moment, la major part d'eines de cerca de les biblioteques són tot el contrari. Normalment, demanem als usuaris dels nostres diferents catàlegs i índexs que seleccionin un camp de cerca, com ara l'autor o el títol, que permet que el sistema no hagi de funcionar bé sense aquest coneixement previ. Els sistemes actuals, com ara Google i Amazon, han deixat clar als usuaris que els sistemes poden funcionar bé sense aquesta orientació i, per tant, tenen menys paciència amb els sistemes que requereixen aquest tipus d'atencions.
Sens dubte, el disseny de sistemes serà clau a l'hora de crear eines de cerca usables, però les metadades també seran importants. Malgrat que cada vegada es digitalitzen més arxius impresos i, per tant, s'hi pot buscar paraules clau, les metadades continuen sent essencials per a la desambiguació, el filtratge, la tria i la classificació.
Tot i que la nostra necessitat de descripció bibliogràfica no disminueix, hem de trobar maneres de crear-la, enriquir-la i gestionar-la més eficientment. Les biblioteques disposen de menys recursos per destinar a processos meticulosos. Així, doncs, el nostre repte és força clar: ser radicalment més eficients en els nostres procediments descriptius, utilitzar tècniques innovadores per aprofitar altres fonts per a la descripció —incloses les comunitats d'usuaris— i usar el poder de les màquines amb més eficàcia i amb menys recursos.
Cooperació global
Les biblioteques de tot el món tenen molt a veure les unes amb les altres. Molts dels nostres procediments, serveis, objectius i estratègies són els mateixos. Si cooperem a escala global podem començar a repartir els beneficis de la informàtica a escala web per totes les biblioteques del món. Les millors possibilitats les ofereix OCLC, una organització de socis sense ànim de lucre que "es dedica als interessos públics de promoure l'accés a la informació mundial i reduir la taxa de creixement dels costos de la biblioteca. Més de 71.000 biblioteques de 112 països i territoris de tot el món utilitzen els serveis d'OCLC per localitzar, adquirir, catalogar, deixar en préstec i preservar els materials de les biblioteques".4
El servei insígnia d'OCLC és WorldCat, el catàleg associat de fons de biblioteques. Consultable per qualsevol persona a través de WorldCat.org, actualment té més de 135 milions d'arxius amb més de 1.400 milions de documents relacionats.5 Com que s'hi incorporen els fons de més biblioteques d'arreu del món, incloses les principals biblioteques nacionals, representa la diversitat lingüística i cultural mundial.
A partir d'aquesta enorme base de dades es poden crear diversos serveis. Per exemple, WorldCat Identities (disponible directament a <http://worldcat.org/identities/>, o bé integrat com a part de WorldCat.org) ofereix una única pàgina web que conté molta informació sobre els autors, que s'ha extret mitjançant programari de les dades incloses a WorldCat. A més, també hi ha enllaços des d'aquestes pàgines a altres fonts d'informació sobre els autors.
Hi ha moltes més oportunitats de cooperació a escala regional o global. Sens dubte, el projecte Europeana n'és un exemple (disponible a <http://www.europeana.eu/>). Si treballem plegats, tenim moltes més possibilitats d'acomplir els nostres objectius que si treballem per separat.
Remuntar la cadena
Durant molts anys les biblioteques han creat metadades (catalogació) inspeccionant el títol de les pàgines i el títol del revers de les pàgines d'un llibre i arxivant diversos bits d'informació sobre l'obra, assignant-hi termes sobre la temàtica i classificació, etc. Això ha estat necessari perquè no hi havia cap altra manera d'obtenir informació en un format usable (és a dir, llegible per l'ordinador). Aquests dies estan desapareixent a marxes forçades i, tot i així, la majoria dels nostres processos continuen sent els mateixos.
El que ha canviat és com es produeixen, distribueixen i venen els llibres. Avui en dia, les metadades abracen tota la cadena de venda dels llibres, des dels editors als venedors a l'engròs o al detall. Amazon ho exigeix, com fan molts detallistes. El que Amazon demana és que els editors proporcionin informació sobre els llibres que tenen per vendre en el format ONIX XML.6 Aquest fet permet a Amazon tractar amb eficàcia la gran quantitat de productes que ha de gestionar per obtenir un benefici. Mentrestant, tot i que les editorials sovint ofereixen descripcions riques dels llibres en un format llegible per la màquina (moltes de les quals inclouen un resum, una biografia breu de l'autor, fragments de citacions de ressenyes, etc.), fins ara les biblioteques han ignorat aquestes descripcions.
Per canviar-ho, i alhora crear potencialment un nou servei per a les editorials, OCLC ha creat el projecte Next Generation Cataloging. El lloc web descriu les funcions dels diferents implicats i què esperen aconseguir:
La funció dels editors i venedors: els editors i venedors de la mostra ofereixen a OCLC informació sobre títols en format ONIX. OCLC converteix les dades a MARC per afegir-les a WorldCat i, si escau, enriqueix les dades automàticament mitjançant mineria i mapatge de dades. Les metadades enriquides es retornen als editors i venedors en format ONIX perquè valorin les millores d'OCLC.
La funció de les biblioteques: les biblioteques de la mostra valoren la qualitat de les metadades afegides a WorldCat amb aquest procés i ofereixen una retroalimentació sobre la pertinència d'usar-les en cicles de treball dels serveis tècnics de la biblioteca.
La funció d'altres implicats: altres entitats implicades de la indústria editorial, com ara BISG (Book Industry Study Group, Inc.), col·laboren amb OCLC amb estàndards de dades i terminologia de la indústria editorial, i també proporcionen un fòrum en el qual compartir idees i resultats amb la indústria.7
Per mitjà de projectes com aquest, esperem que les biblioteques puguin usar més eficaçment les metadades que creen les editorials, tant per reduir el nostre volum de feina, com per enriquir els nostres arxius amb contingut que abans no era disponible, com ara resums.
Mineria de dades
És possible que qualsevol incorporació notable de dades ofereixi oportunitats per "fer-ne una mineria" i trobar informació que només es pot descobrir quan es troba en grans quantitats en un lloc. Per exemple, fa uns quants anys, OCLC va començar a fer servir el nombre de biblioteques que tenien un llibre en el fons per incrementar la classificació d'importància dels resultats de cerca del WorldCat. És a dir, com més biblioteques tenien un llibre, més alta era la classificació en els resultats de cerca. Només si disposes d'una incorporació considerable d'aquest tipus de dades pots aprofitar una oportunitat com aquesta.
OCLC també es planteja l'ús de camps i subcamps MARC en tota la base de dades WorldCat, per veure què se'n pot extreure. Els meus col·legues que fan recerca a OCLC tenen nombrosos projectes que s'hi relacionen, sota la categoria àmplia de "Renovar pràctiques descriptives i organitzatives".8
Enriquir les dades
Als arxius típics d'un catàleg de biblioteca, per molta feina que comporti crear-los, encara els falten moltes coses que els nostres usuaris voldrien veure-hi. No s'hauria de poder veure tot el text en línia, qualsevol part de l'obra, com ara l'índex de continguts, l'índex onomàstic, la coberta, etc. perquè l'usuari pogués decidir si realment necessita veure el llibre?
Com s'ha esmentat abans, els arxius ONIX de les editorials ofereixen a les biblioteques un mètode potencial per enriquir les nostres descripcions bibliogràfiques amb informació addicional que els usuaris troben útil. També s'han fet uns quants intents de digitalitzar els índexs de continguts i que s'hi pugui accedir amb més facilitat. Potser el projecte d'aquest tipus més conegut és el del Bibliographic Enrichment Advisory Team (BEAT) de la Biblioteca del Congrés dels Estats Units, que ha proveït informació ampliada per a centenars de milers d'arxius bibliotecaris.9
A mesura que s'incorporen més dades bibliotecàries en un lloc, sorgeixen més oportunitats de mineria de dades, com s'ha comentat més amunt. Una d'aquestes oportunitats que ha explorat OCLC és un experiment amb una classificació sobre el "nivell del públic". Tal com indica la pàgina web del projecte: "Aquest projecte de recerca estudia la possibilitat de fer servir els fons bibliotecaris al WorldCat per calcular indicadors sobre el nivell de l'audiència respecte dels llibres representats a la base de dades WorldCat, d'acord amb els tipus de biblioteques que tenen els títols".10 Aquest indicador es podria utilitzar per filtrar els resultats de cerca d'acord amb la rellevància per a un usuari concret. Per exemple, potser un investigador universitari no estarà interessat en ítems destinats al públic d'una escola primària.
Autoritzar els usuaris per afegir valor
Tal com han descobert moltes empreses, els usuaris d'Internet sovint disposen d'informació de valor per donar, si se'ls brinda l'oportunitat. Les institucions encarregades del patrimoni cultural comencen a permetre que els usuaris contribueixin amb etiquetes, ressenyes, classificacions i altres tipus de millora a les descripcions estàndards de bibliotecaris, arxivers i curadors.
El projecte Steve.museum ha investigat sobre l'etiquetatge dels usuaris d'objectes del museu digital i fins ara sembla que les conclusions mostren un gran potencial per millorar la recuperació d'objectes del museu si es permet que els usuaris etiquetin els ítems amb la seva terminologia.11 "Les etiquetes socials i la folksonomia podrien ser una aportació positiva a l'accessibilitat de les col·leccions d'art dels museus en línia", assenyala Jennifer Trant, membre del projecte.12
En la imatge següent, Trant il·lustra que mentre que els museus poden estar interessats a documentar una sèrie de característiques sobre un objecte, els usuaris poden embellir la descripció amb paraules que tinguin un sentit per a ells.
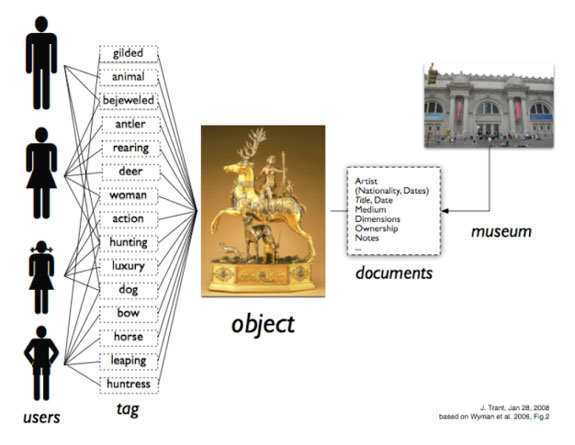
Figura 1. Diferents visions sobre la documentació d'un objecte: mentre que els usuaris etiqueten
des de múltiples perspectives, el museu documenta des d'un punt de vista únic, institucional.13
De la mateixa manera que els qui s'han responsabilitzat de recollir, gestionar i preservar el nostre patrimoni cultural, de vegades nosaltres no ens adonem que els qui no tenen formació en aquestes tasques continuen tenint moltes coses per oferir. Concretament, els qui viuen en una comunitat representada per les nostres col·leccions de fotografies històriques poden tenir molt per oferir. Per exemple, la figura 2 representa un comentari d'un usuari sobre una fotografia històrica del lloc web Maritime History of the Great Lakes, gestionat per la Halton Hills Public Library a Ontario, Canadà.
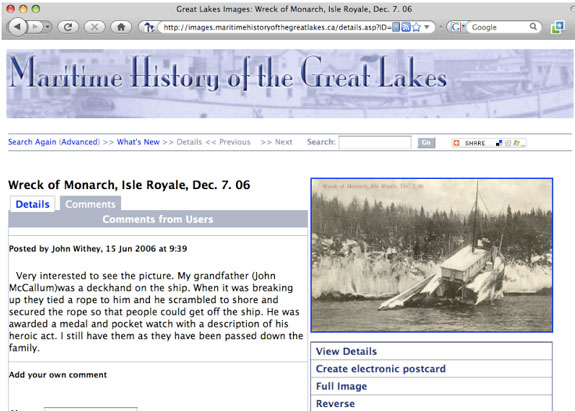
Figura 2. Comentari d'un usuari d'una fotografia històrica al lloc web Maritime History of the Great Lakes,
gestionat per la Halton Hills Public Library d'Ontario, Canadà.
Fer accessibles les dades perquè altres persones les utilitzin
Les dades bibliogràfiques es poden fer servir en molts contextos diferents per proveir diversos serveis útils. Per facilitar que aquestes dades "es barregin" amb altres dades de nous tipus de serveis cal fer-les accessibles al programari per mitjà de protocols i formats estructurats, és a dir, XML.
Les tres opcions principals d'exposar les dades bibliogràfiques perquè altres persones les utilitzin tenen lloc via una interfície de programació d'aplicacions (API), via l'Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH)14 i com a dades enllaçades.
Interfície de programació d'aplicacions (API)
Les API són una manera útil d'exposar les dades bibliogràfiques quan no volem oferir-les perquè siguin recollides o descarregades. Tanmateix, cada vegada que una aplicació fa servir les teves dades, el teu servidor és cridat per aquesta aplicació. És possible que les biblioteques no vulguin allotjar aquest tipus de trànsit de dades; per això, la recollida podria ser un mètode millor per exposar les dades. TechEssence.info manté una llista de biblioteques relacionades amb API.15
Un bon exemple d'ús d'API en un context bibliotecari és el nombre creixent de serveis web que exposa OCLC mitjançant la seva iniciativa Grid Services. Aquests serveis els facilita el Developer Network d'OCLC, en què es poden trobar múltiples serveis de suport al desenvolupador: documentació de serveis, codi de mostra, una llista de correu i un blog, etc.16 Hi ha disponibles una dotzena de serveis independents, i no se'n deixen d'afegir de nous.
Recollida
Proporcionar dades bibliogràfiques perquè es recullin significa donar suport a l'Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH), que és força senzill i ja forma part de moltes aplicacions de programari de biblioteques. Probablement, totes les aplicacions de programari dels repositoris de les institucions admeten aquest protocol, i algunes de les més importants són DSpace, Fedora, ePrints i CONTENTdm.
El protocol en si mateix és força senzill, ja que només es transporten via HTTP sis verbs com a petició de transferència d'estat representacional (REST). L'únic format de metadades necessari és Dublin Core, però alguns llocs n'admeten d'altres, formats de metadades més rics per ser descarregats, com ara MARCXML i/o MODS.
Dades enllaçades
Tal com indica l'apartat de PMF sobre dades enllaçades d'Structured Dynamics, "les dades enllaçades són una sèrie de bones pràctiques per publicar i mostrar exemples i classificar dades utilitzant el model de dades RDF, anomenar els objectes de dades fent servir identificadors uniformes de recursos (URI), de manera que s'exposin les dades per accedir-hi via el protocol HTTP, mentre s'emfatitzen les interconnexions de dades, interrelacions i contextos útils tant per als humans com per a les màquines".17
Una manera més senzilla de descriure les dades enllaçades seria: un conjunt de bones pràctiques per exposar dades estructurades al web en un format usable per les aplicacions de programari. A més, la finalitat de les dades enllaçades és permetre connexions entre conjunts de dades relacionades, de manera que es permetin diverses aplicacions potencials que no serien possibles sense aquests enllaços.
Un exemple excel·lent de dades enllaçades és el lloc web Authorities and Vocabularies de la Biblioteca del Congrés.18 Actualment, aquest lloc proveeix el vocabulari de paraules clau d'encapçalaments relacionades amb la Biblioteca del Congrés per descarregar-lo, buscar-hi i enllaçar-hi. El programari pot sol·licitar l'arxiu d'una paraula clau d'encapçalament concreta, retornar-lo en un dels diversos formats estructurals i descobrir termes més amplis o menors, o relacionats, i també els identificadors (URL) d'aquests termes dins el conjunt de dades.
Encara no és clar què permetrà el fet d'exposar dades estructurades d'aquesta manera, però si no ho fem no ho sabrem mai. Com a mínim, avui dia, qualsevol que vulgui tenir accés a aquest vocabulari important el pot obtenir d'una manera usable per programari.
Exposar les dades on la gent es congrega
Tot i que les biblioteques han invertit una gran quantitat de temps i de diners en la construcció de portals perquè els usuaris descobreixin el contingut de les biblioteques —tant imprès com digital—, és clar que la gran majoria d'usuaris d'Internet no coneixen aquests llocs i no acaben descobrint bona part de les riqueses digitals que comencem a acumular en línia.
Per intentar abordar aquest problema, l'any passat la Biblioteca del Congrés va començar un experiment per exposar part del seu contingut digital a Flickr.com. Anomenat Flickr Commons, la Biblioteca del Congrés va presentar unes 3.000 fotografies en blanc i negre i en color de dues col·leccions. Els resultats són impressionants:
En les primeres 24 hores després del llançament, Flickr va registrar 1,1 milions de visualitzacions totals en el nostre compte; una setmana més tard, el compte havia rebut 3,6 milions de visualitzacions de la pàgina i 1,9 milions de visites totals. Això incloïa més de 2 milions de visualitzacions de les fotos i més d'1 milió de visualitzacions del flux de fotos. Al començament d'octubre, les fotos de la Biblioteca del Congrés tenien, de mitjana, unes 500.000 visualitzacions al mes i havien traspassat el llindar de 10 milions de visualitzacions totals i el llindar de 6 milions de visites.19
El motiu d'aquest trànsit tan sorprenent és senzill: Flickr.com és un lloc que freqüenten molts usuaris i, per tant, exposar el contingut que prèviament quedava "ocult" en un portal que visitaven sovint els va cridar l'atenció sobre aquest material.
Els llocs web que calculen el trànsit poden il·lustrar la disparitat entre les visites al lloc web de la Biblioteca del Congrés i a Flickr.com. Per exemple, la figura 3 il·lustra la classificació del trànsit d'aquests dos llocs elaborada per Alexa.com. Flickr.com està classificat en la 33a posició quant a trànsit en el moment d'escriure aquest text i la Biblioteca del Congrés, en el lloc 2.904. Tot i que una classificació per sota de 3.000 continua sent respectable, la diferència entre tots dos és significativa.
Les biblioteques, museus i arxius tenen continguts interessants, però sense exposar-los on la gent els pugui trobar continuaran sent desconeguts i quedaran sense utilitzar.
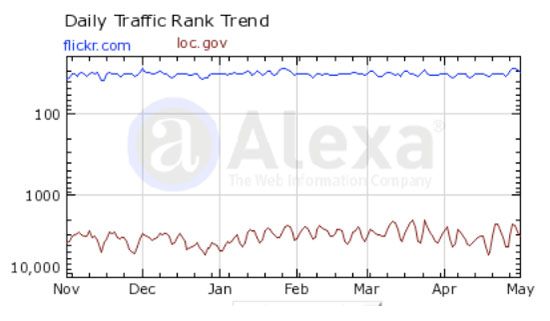
Figura 3. Tendència del trànsit diari d'Alexa per a Flickr.com i Loc.gov, novembre de 2008 - començament de maig de 2009
Permetre la interacció efectiva amb els usuaris
Durant molts anys, les nostres eines de cerca bibliogràfica amb prou feines han progressat a l'hora de permetre la interacció efectiva amb els usuaris. Fins ara, malgrat proves de llocs com ara Amazon en què la cerca pot ser menys costosa, la majoria de les nostres eines de cerca bibliogràfica fan servir una tecnologia que era innovadora en la dècada de 1980. Per això, recentment, molts escriptors han menyspreat els sistemes de catalogació de les biblioteques (sovint anomenats, com si es volgués consolidar la natura anacrònica d'aquests sistemes, catàlegs d'accés públic en línia o OPAC), perquè no són intuïtius, són difícils d'utilitzar i ineficaços.20
Tot i així, els últims anys hi ha hagut una eclosió d'experiments que s'esforcen a resoldre aquest problema. Un dels primers experiments amb èxit a l'hora de recrear la nostra eina de cerca bibliogràfica primordial va ser el catàleg de la Universitat Estatal de Carolina del Nord (NCSU) - Endeca. En associació amb Endeca, una companyia que abans d'aquest projecte era coneguda, bàsicament, per proveir el programari per a llocs de catàlegs com ara L.L. Bean, l'NCSU va demostrar el poder de la navegació facetada en un context bibliogràfic.21
Els sistemes de catalogació de biblioteques de codi obert, com ara Koha (vegeu <http://koha.org/>) i Evergreen (vegeu <http://www.open-ils.org/>), amplien els límits de les eines de descoberta bibliogràfica de les biblioteques i alhora permeten que la gent vegi el codi i hi faci canvis.
Amb la creació d'una nova eina d'indexació de textos creada per a la navegació facetada, anomenada Solr (vegeu <http://lucene.apache.org/solr/>), com a mínim dos projectes bibliotecaris han creat sistemes basats en aquesta plataforma. El Projecte VUFind, de la William Falvey Memorial Library of Villanova University, l'han adoptat diverses biblioteques, inclosa la Biblioteca Nacional d'Austràlia.22 Un altre projecte construït sobre la plataforma Solr és Blacklight, de la Universitat de Virgínia (vegeu <http://blacklightopac.org/>). Tant el VUFind com el Blacklight només són eines de cerca, la qual cosa significa que les biblioteques també continuen necessitant moltes de les funcions del típic sistema integrat de biblioteques (ILS).
Eines per al futur
Amb independència del futur que ens esperi, sabem que ens enfrontem a canvis sistèmics, extensos, en l'execució de les descripcions bibliogràfiques. Si les estratègies concretes que he descrit més amunt són útils o perjudicials només el temps ens ho dirà. Però em sembla evident que hi ha algunes estratègies professionals concretes que ens poden ajudar a afrontar un futur incert amb força i resistència.
Relacions amb els altres integrants de la cadena. Tot i que les biblioteques no han estat mai soles en la creació de dades bibliogràfiques, podríem defensar que hem estat aïllades. Els nostres estàndards professionals només són nostres —no hi ha cap altra professió que hagi adoptat MARC, per exemple, com a estàndard bibliogràfic central, o Z39.50 com a protocol de cerca essencial. Fins i tot l'estàndard OpenURL, escrit específicament i extensament en la seva encarnació 1.0 per afavorir que s'adoptés d'una manera més àmplia, han arrelat poc o gairebé gens fora de les biblioteques. Això s'ha d'acabar.
Les xarxes informàtiques mundials fan que ara sigui possible el que abans semblava problemàtic o gairebé impossible. Avui dia, podem col·laborar amb molta més facilitat amb els editors, distribuïdors i venedors de dades bibliogràfiques i llibreries: tots comparteixen l'interès per les dades bibliogràfiques. En aquesta comunitat, les biblioteques tenen un endarreriment virtual, en què les dades bibliogràfiques se solen crear des de zero fent servir processos manuals i procediments arcans. Mentrestant, les editorials creen una gran quantitat de dades abans que un llibre s'arribi a publicar, des de descripcions bibliogràfiques bàsiques, fins a resums, biografies d'autors i citacions de ressenyes.
Establir relacions fortes i beneficioses mútuament amb cadascun dels integrants de la cadena de la custòdia bibliogràfica només pot servir a les biblioteques per ser més eficients i més efectives. Però fer-ho pot comportar cedir part de la nostra vella autonomia. Per exemple, podria tenir cada vegada menys sentit que disposéssim del nostre format de descripció bibliogràfica. Si el format ONIX que utilitzen les editorials pot satisfer potencialment les nostres necessitats, per què hauríem de continuar usant MARC? Què podríem guanyar d'aquest aïllament continuat? Quines oportunitats ens perdrem si continuem en un aïllament bibliogràfic? Aquestes preguntes esdevenen completament pertinents atesos els esforços per refer la nostra infraestructura bibliogràfica per mitjà de l'esforç d'accés i descripció de recursos (RDA) (vegeu <http://www.rdaonline.org/>). No ens podem permetre esperar, però la nostra direcció professional sembla estar fixada en un camí totalment diferent.
Facilitat amb diferents formats bibliogràfics. El dilema de tenir nombrosos formats bibliogràfics (com a mínim, un utilitzat pels de fora de la comunitat de biblioteques, per exemple, ONIX, i múltiples formats dins de la comunitat de biblioteques, per exemple, MARC, MODS) implica que hem de tenir facilitat per utilitzar-los. Hem deixat de ser una professió centrada només en MARC; no ho podem ser. Per tant, se'ns ha de donar bé traduir formats i comprendre'n els punts forts i els punts febles de cadascun. Necessitarem noves eines per analitzar metadades, normalitzar-les, representar-les visualment de maneres útils i fer-hi canvis sistèmics.
Actualització professional. Han quedat enrere els dies en què un bibliotecari podia sortir de la facultat satisfet amb si mateix per estar ben format davant del que es podia esperar trobar al llarg de la seva carrera professional. Un títol en biblioteconomia no s'hauria de considerar un punt final, sinó un inici, la base sobre la qual algú construeix al llarg de la seva vida una carrera amb aprenentatge i actualització constants.
Crear el nostre futur bibliogràfic avui
No hi ha cap dubte que ens enfrontem a molts reptes en un món en què Google digitalitza i proveeix la cerca de text complet de milions de llibres que tenen les biblioteques. La funció de la descripció bibliotecària ha canviat per sempre en un món com aquest. Descobrir ja no es limita a les descripcions que els catalogadors decideixen crear. Tanmateix, encara crec que la descripció bibliogràfica estructurada continua sent útil. Però necessitem fer-la d'una altra manera diferent de com ho fem actualment, hem de treballar amb altres persones que tenen informació i procediments per contribuir, i hem d'exposar-la en llocs molt diferents i de maneres molt diverses.
Les estratègies descrites més amunt només són, en realitat, la punta d'un iceberg que encara hem d'acabar d'entendre del tot. I la nostra comprensió evolucionarà amb l'entorn, la qual cosa significa que hem d'estar contents si som sempre com a mínim un pas per darrere d'on hem d'estar. Però ser més d'un pas enrere comporta perdre el nostre futur davant d'altres que el crearan per nosaltres. Prefereixo un futur diferent.
Notes
1 Per exemple, University of California Libraries Bibliographic Services Task Force. Final report, December 2005. <http://libraries.universityofcalifornia.edu/sopag/BSTF/FinalsansBiblio.pdf>; Calhoun, Karen, The Changing Nature of the Catalog and its Integration with Other Discovery Tools, 21 de febrer de 2006. <http://dspace.library.cornell.edu/bitstream/1813/2670/1/LC+64+report+draft2b.pdf>; Library of Congress Working Group on the Future of Bibliographic Control, On the Record: Report of The Library of Congress Working Group on the Future of Bibliographic Control, 9 de gener de 2008. <http://www.loc.gov/bibliographic-future/news/lcwg-ontherecord-jan08-final.pdf>.
2 Tennant, Roy. "The Future of Descriptive Enrichment" [article d'un blog]. <http://www.libraryjournal.com/blog/1090000309/post/1920018592.html>.
3 Parafrasejat a: Stephens, Owen. "ALA 2008: There's no catalog like no catalog - the ultimate debate on the future of the library catalog" [article d'un blog]. <http://www.meanboyfriend.com/overdue_ideas/2008/06/ala-2008-theres-no-catalog-like-no-catalog---the-ultimate-debate-onf-the-future-of-the-library-catalog.html>.
4 "About OCLC". <http://www.oclc.org/us/en/about/>.
5 "Facts and Statistics". <http://www.oclc.org/us/en/worldcat/statistics/>.
6 "ONIX for Books". <http://www.editeur.org/onix.html>.
7 "Next Generation Cataloging". <http://www.oclc.org/partnerships/material/nexgen/nextgencataloging.htm>.
8 "Renovating Descriptive and Organizing Practices". <http://www.oclc.org/programs/ourwork/renovating/>.
9 "Bibliographic Enrichment Advisory Team". <http://www.loc.gov/catdir/beat/>.
10 "Audience Level". <http://www.oclc.org/research/projects/audience/>.
11 Steve.museum. "Links and Resources". <http://steve.museum/?option=com_content&task=blogsection&id=5&Itemid=14>.
12 Trant, J. "Tagging, Folksonomies and Art Museums: Early Experiments and Ongoing Research". Journal of Digital Information, 2009, vol. 10, núm. 1, p. 39. <http://journals.tdl.org/jodi/article/view/269/278>.
13 Ibíd., p. 3.
14 The Open Archives Initiative Protocol for Metadata Harvesting. <http://www.openarchives.org/OAI/openarchivesprotocol.html>.
15 TechEssence.info. "Library Application Program Interfaces (APIs)". <http://techessence.info/apis/>.
16 OCLC Developer Network. <http://worldcat.org/devnet/>.
17 Structured Dynamics. "Linked Data FAQ". <http://structureddynamics.com/linked_data.html>.
18 Library of Congress. "Authorities and Vocabularies". <http://id.loc.gov/>.
19 Springer, Michelle; Dulabahn, Beth; Michel, Phil, et. al. For the Common Good: The Library of Congress and the Flickr Pilot Project. Washington, DC: Library of Congress, 30 d'octubre de 2008. <http://www.loc.gov/rr/print/flickr_report_final.pdf>.
20 En són dos exemples: Schneider, Karen. "How OPACs Suck, Parts 1-3". ALA TechSource Blog. <http://www.techsource.ala.org/blog/2006/05/how-opacs-suck-part-3-the-big-picture.html>, i University of California Libraries Bibliographic Services Task Force. Informe final de desembre de 2005. <http://libraries.universityofcalifornia.edu/sopag/BSTF/FinalsansBiblio.pdf>.
21 Antelman, K.; Lynema, E.; Pace, A. "Toward a 21st Century Library Catalog". Information Technology and Libraries, 2006, 25(3). <http://eprints.rclis.org/7332/>.
22 VUFind. <http://vufind.org/>. Open Source at the National Library of Australia Catalogue. <http://www.nla.gov.au/pub/gateways/issues/92/story02.html>.