Tony Hernández-Pérez
Departamento de Biblioteconomía y Documentación
Universidad Carlos III de Madrid
Google Dataset Seach: beta. Disponible a: <https://toolbox.google.com/datasetsearch>. [Consulta: 16/10/2018].

L’any 2018 està sent molt entretingut en el món de la comunicació científica. A la primera part de l’any es van presentar tres grans bases de dades acadèmiques 1Findr (de 1Science’s), Dimensions (de Digital Science) i Lens (de Cambia, una ONG australiana, que, a més d’articles científics, recull fins i tot patents). De sobte, tres grans bases de dades que aspiren a competir amb la capsa blanca, més aviat negra, de Google Scholar i de Microsoft Academic. I tornant de l’estiu, dues altres grans sorpreses: el controvertit Plan S, una iniciativa de 12 de les més importants agències nacionals de finançament de la recerca a Europa. Un pla la intenció del qual és obligar científics i investigadors beneficiaris de fons públics de recerca per tal que el 2020 publiquin els seus treballs de forma immediata només en repositoris o revistes d’accés obert, excloent fins i tot les revistes híbrides. Una iniciativa que ha enutjat molt, entre d’altres, gran part del sector editorial, que el perceben com una gran amenaça. I gairebé el mateix dia, el 5 de setembre de 2018, Google va fer públic el llançament d’un nou producte: Google Dataset Search, l’objectiu del qual és facilitar l’accés als milions de datasets existents en milers de repositoris a la web.
Google aspira a convertir el seu nou producte en «el Google Scholar de les dades»: el lloc on es poden descobrir els datasets de qualitat que serveixin als investigadors, als periodistes i a tots aquells ciutadans interessats a disposar de dades procedents de fonts de qualitat. La hipòtesi de treball de Google amb el nou producte ha estat «Construeix-lo i vindran» i no els ha faltat raó. El cercador, encara en fase beta i amb moltes limitacions, ha aixecat moltes expectatives, segurament, perquè contribueix a resoldre un greu problema: la dispersió de fonts en les quals es troben els conjunts de dades més rellevants, tant els produïts pels governs (dades obertes governamentals) com els produïts pels investigadors (dades obertes de recerca).
Actualment, cercar datasets resulta extremadament problemàtic, no tan sols pels múltiples esquemes de metadades que s’utilitzen per descriure els datasets sinó també per la multitud de repositoris de dades que existeixen. El directori de repositoris de dades científics més important, el Registry of Research Data Repositories recull ja més de 2.200 repositoris, 24 a Espanya, alguns especialitzats en un tema, d’altres, com Zenodo, Mendeley o Figshare, més generalistes, on es pot trobar gairebé qualsevol tema. Nature recomana dipositar les dades que serveixen de base a les seves publicacions en més de 50 repositoris diferents. I els repositoris de dades obertes governamentals es troben igualment dispersos. De vegades, accessibles a través d’un agregador i d’altres és necessari anar a buscar a cada ajuntament, ministeri o agència governamental. Un caos per a l’usuari final, que finalment no sap en quin dipòsit de dades buscar, que està obligat a utilitzar una interfície diferent per a cada lloc i a obtenir descripcions molt diverses d’aquests datasets.
Amb el seu nou producte, Google pretén contribuir a allò que ells anomenen un «fort ecosistema de dades obertes» mitjançant el foment d’estàndards oberts de metadades per descriure els datasets publicats. A les seves directrius, Google adverteix que només recol·lectarà datasets de pàgines web que continguin dades estructurades. I recomana l’ús del tipus de contingut Datasets, del consorci schema.org o estructures equivalents representades al Data Catalog Vocabulary (DCAT) del W3C, una bona notícia per a molts dels catàlegs de dades obertes governamentals, molts utilitzen aquest vocabulari, que podran veure un augment en l’accés als seus datasets si aquest producte de Google es popularitza. La idea és clara, si el robot de Google descobreix les teves pàgines web amb dades estructurades que continguin datasets, els recollirà, si no… les tractarà com una pàgina més però no entrarà en el seu índex de datasets i tindrà més risc de perdre’s en la llarga cua de resultats.
Google intenta, a més, fomentar la cultura de la citació de dades, de forma similar a com citem les publicacions, per reconèixer el mèrit a aquells que creen i publiquen dades. De fet, a les seves pàgines de resultats ja es poden apreciar missatges del tipus «4 articles acadèmics citen aquest conjunt de dades (Vegeu-ho a Google Acadèmic)», amb la qual cosa, al mateix temps, Google enllaça els datasets amb els treballs de recerca indexats a Google Scholar. Encara és aviat per saber si el sistema serà reversible. Des dels articles es podrà accedir als datasets indexats per Google? Està Google pensant a contribuir a aquesta cultura afegint un botó per citar les dades d’acord a l’esquema de metadades de Datacite o un altre de similar?
Google Dataset Search, a diferència del seu cercador general, treballarà exclusivament amb metadades. Així i tot, el repte no és menor: després que el robot descobreixi els datasets haurà de realitzar una operació de «neteja de dades», malgrat les dades estructurades, és necessari normalitzar dates, detectar diferents autors i assegurar-se que les metadades estan ben assignades perquè aquestes metadades acostumen a arribar amb dades incompletes, errònies o directament omeses; Google haurà d’identificar les rèpliques, donat que un mateix dataset pot estar dipositat en diversos repositoris al mateix temps, o ser un subconjunt d’un dataset amb un major nivell d’agregació. A continuació, passarà la informació pel seu gràfic de coneixement (Knowledge Graph), la base de dades de coneixement que utilitza Google per detectar entitats, llocs, etc. i entendre el context de la pàgina que està analitzant. I, finalment, intentarà enllaçar el dataset amb Google Scholar. El que construeix Google és, doncs, un gegantesc índex de metadades netes i enriquides que serà la base de dades on busquem els usuaris. Així, la qualitat de la base de dades serà major o menor en funció de la qualitat de les metadades que assignen els proveïdors dels datasets.
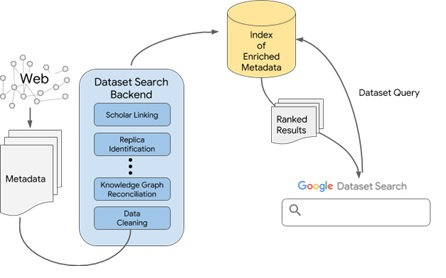
Esquema del funcionament de Google Dataset Search
Font: https://ai.googleblog.com/2018/09/building-google-dataset-search-and.html
El producte, com dèiem, està en fase beta. Google encara no sap com busquem els usuaris datasets i espera poder aprendre de l’ús que fem del cercador per poder millorar-lo. Per ara, no se saben els criteris amb els quals mostra el rànquing de resultats, no se sap si utilitza la fiabilitat de la font, el nombre de cites del dataset a Google Scholar, la data d’actualització o de cobertura temporal o qualsevol altre criteri. La interfície dels resultats és molt millorable: no ofereix ni tan sols els resultats aproximats a una cerca; les descripcions dels diferents datasets són molt dispars; amb prou feines es mostren de tres a cinc resultats; no permet filtrats de quasi cap tipus, encara que sembla que funciona l’operador site: xxx.xx per limitar les cerques; no hi ha cerca avançada ni cap ajuda de com buscar. I, com a Google Scholar, per desgràcia, no proporciona cap API (application programming interface). I, per ara, no resulta fàcil trobar una llista dels repositoris que estan indexant, més enllà d’alguns dels grans repositoris que d’alguna forma estan contribuint activament a l’arrencada de Google Dataset Search (NOAA, ICPSR, Dataverse…) complint amb les directrius de Google per publicar datasets.
La major part dels grans repositoris, com Zenodo, Dryad o Figshare suporten i descriuen en JSON-LD els seus datasets d’acord a schema.org. No obstant, molts repositoris que han estat emmagatzemant datasets dels seus investigadors no treballen encara amb schema.org, per la qual cosa, si es vol augmentar la visibilitat dels datasets per després intentar fer un seguiment de les seves citacions i del seu ús, caldrà anar preparant-se. En qualsevol cas, per a aquells datasets als quals vulguem donar visibilitat de forma immediata i fins a la implementació d’schema.org al nostre repositori, sempre es pot anar, com fins ara, a registrar el dataset en alguns dels hubs o agregadors que sí que el tinguin implementat, per exemple, a Datacite o a datos.gob.es per al cas de dades obertes governamentals.
L’aparició de Google Dataset Search produeix sensacions enfrontades. D’una banda, pot ajudar a simplificar la cerca de dades obertes, com ha succeït amb Google Scholar. Com que és conscient de la importància de les dades i, per fi, de les metadades, està construint un producte o servei capaç de connectar-se a diferents repositoris, biblioteques digitals, revistes i catàlegs de dades de les administracions i agències governamentals per facilitar a l’usuari final la cerca de dades obertes des d’un únic lloc. Per una altra, l’èxit del servei significarà una mena de punt únic d’accés a totes les dades obertes, una mena de jardí únic i privat de Google, gratis, sí, però privat, perquè serà Google l’únic que tindrà accés a tota la informació i les dades que aquell punt únic d’accés generi. Ara que gràcies als identificadors persistents veiem aparèixer noves bases de dades d’articles científics como Lens, Dimensions o 1Findr potser també veiem aparèixer altres cercadors de datasets alternatius. Tant de bo apareguin aquestes alternatives i tant de bo que Google no deixi morir la seva nova joguina, com tants altres productes.

