

PI: Carles Escera
The Frequency-Following Response (FFR) provides a scalp-recorded microphone of how the spectrotemporal components of auditory stimuli are encoded in subcortical soundtraces (Figure 1). Although the sources of the FFR are still disputed, the current consensus is that these soundtraces emerge in a complex cortico-subcortical network, with major subcortical contributions for frequencies > 100-150 Hz (see our ongoing research on this topic…).
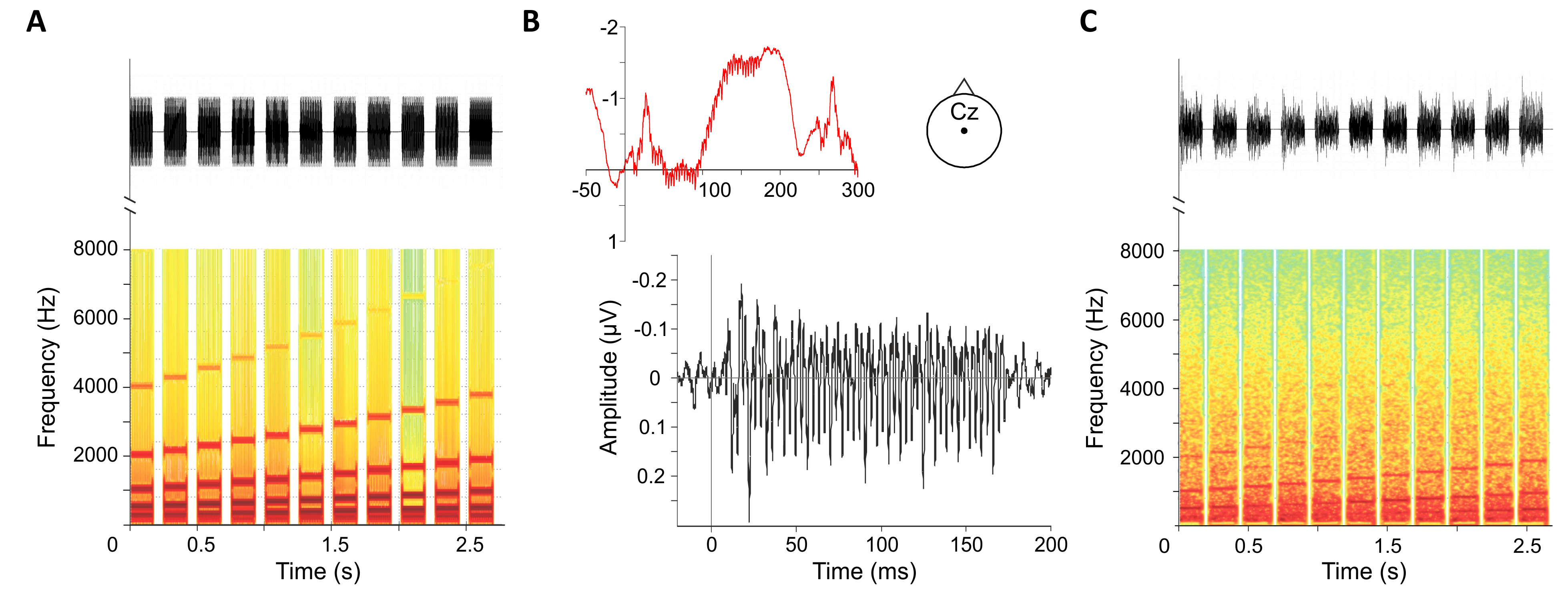
Figure 1. Illustration of the FFR as a proxy of subcortical soundtraces. A) Eleven tones (170 ms) were concatenated (top) to form one Shepard cycle (Shepard, 1964); tones consisted of 12 sinusoidal components at successive one-octave intervals as shown in the spectrogram (bottom; hear it here). B) Grand-average (N=21) open-filter (0.5-3000 Hz) evoked potentials at Cz showing both cortical and overlapping frequency-following components for the first stimulus in the Shepard cycle (red); when the slow components (<80 Hz) are filtered out, the FFR clearly emerges as a steady-state response (black). C) Concatenation of the FFRs elicited to the 11 tones in the Shepard cycle (top) and their spectrogram (bottom), which faithfully resembles that of the stimulus sequence, tough low-passed filtered. Remarkably, when played back through a speaker, the eliciting illusory sound sequence can be “heard” in the soundtraces. Unpublished observations by Grimm, Costa-Faidella and Escera (2013).

The FFR has gained recent interest in auditory cognitive neuroscience as it highlights the importance of deciphering how we make sense of sounds to understand how we use speech, and to conceive the functional auditory system as a distributed, but integrated architecture specialized in computing on-line stimulus statistics (Escera, 2017; Figure 2). Here at the Brainlab we have made use of the FFR to show subcortical prediction errors (Slabu et al., 2012; read more…), the involvement of the serotonin transporter gene in accurate subcortical speech encoding (Selinger et al., 2016; read more…) and that timing predictability enhances subcortical regularity encoding (Gorina-Careta et al., 2016; read more…).
A fascinating feature of the FFR is that it provides a window into complex contingency computing in the subcortical auditory system, and thus were are currently investigating how the low-level auditory system extracts on-line stimulus statistics in complex auditory patterns (Costa-Faidella et al., in preparation) and, in collaboration with Dr. Marta Ortega-Llebaria from University of Pittsburgh (USA), the online predictive modulation of low-level acoustic encoding of lexical expectations (Figure 3).
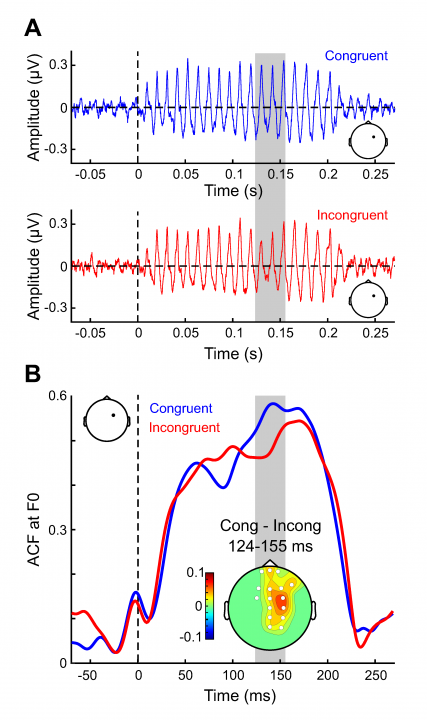
Figure 3. a) The Frequency-Following Response (FFR) elicited to the very same token (vowel /a/) when it closed a word (blue) or pseudoword (red). b) The autocroscorrelgram function disclosing significant differences at 124-155 ms from vowel onset. From Ortega-Llebaria et al. (in preparation).